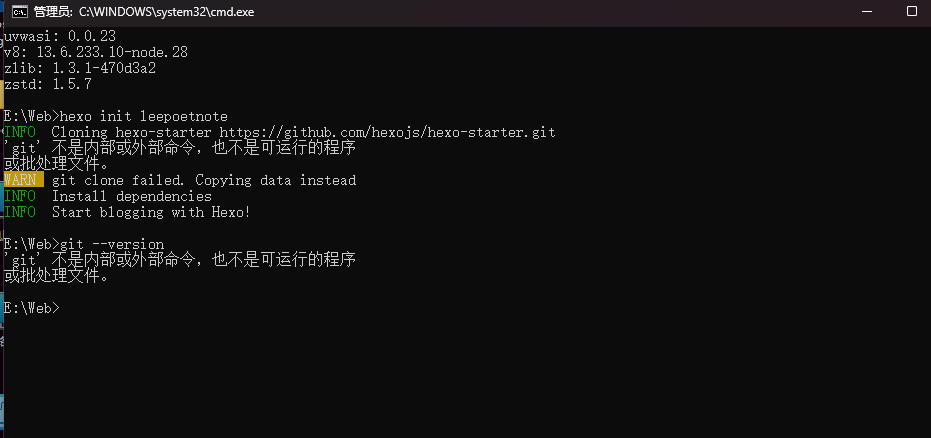
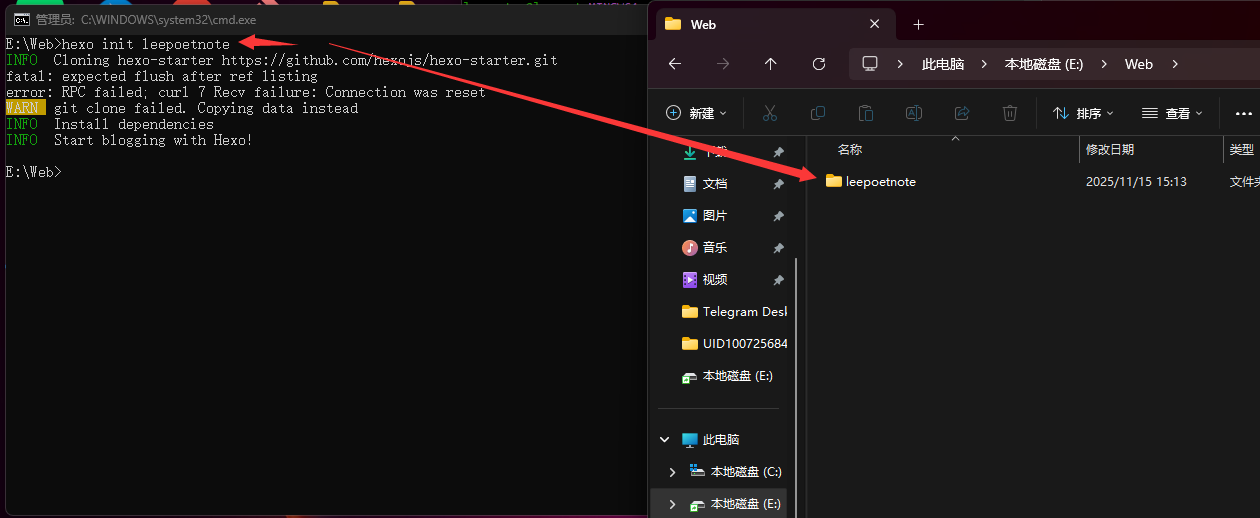
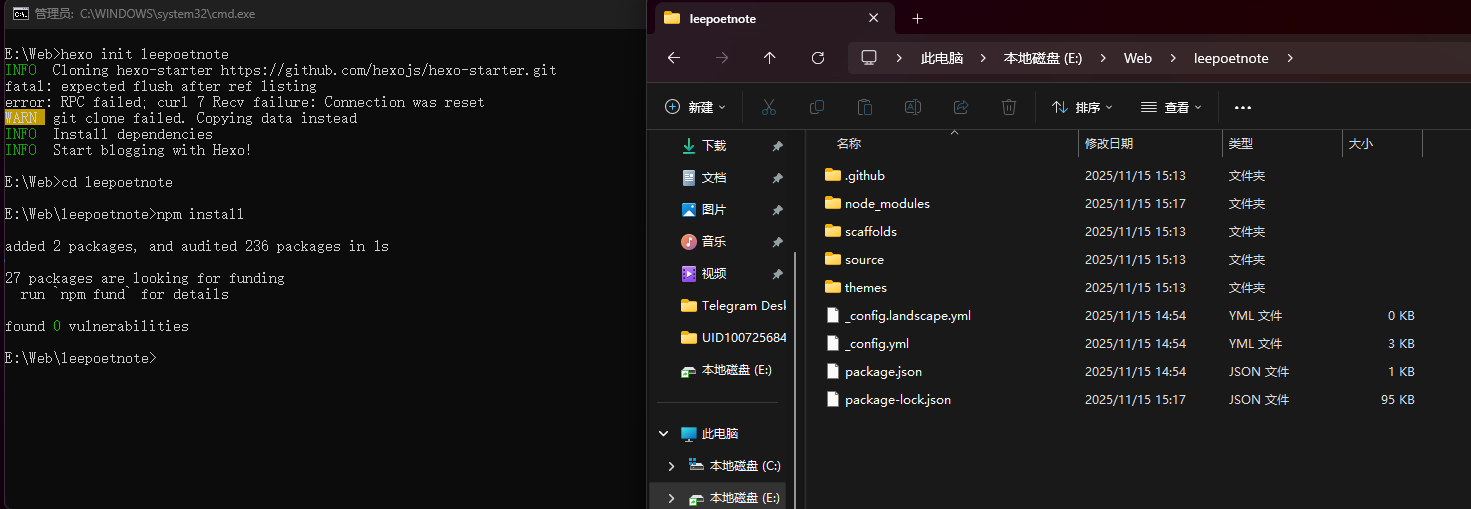
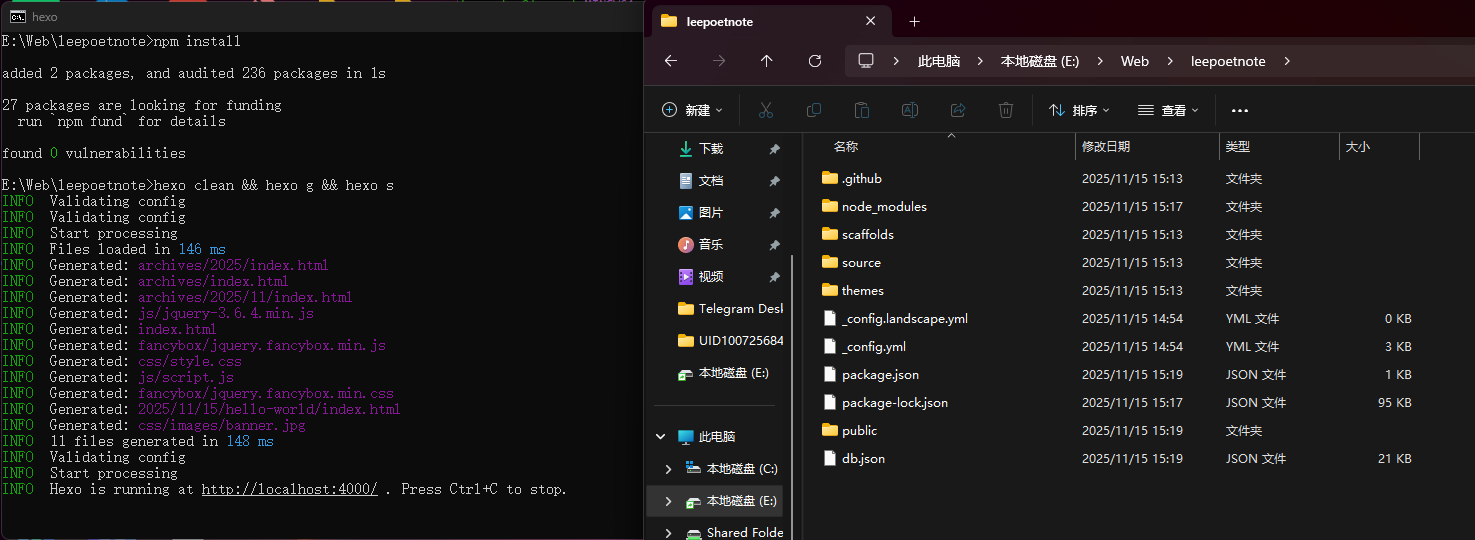
一、怎么在u盘上跑完整的windows呢?我们都知道,操作系统一定要操作……哦不对,常见的操作系统一定要在硬盘上跑。无论是固态硬盘也好,还是机械硬盘也罢,我们概念中的系统一定是装在电脑里的那个固定不动的硬盘上的。一般windows的默认安装位置就是机内的存储介质,并不能像linux那样直接在livecd里就能直接装在u盘上。其实windows to go的历史很久了,可以追溯到2011年:2011 年 4 月,Windows to go就已包含在泄漏的 Windows 8 Build 7850 版本中。同年 9 月,微软在 Build 大会上正式公布了此功能,并分发了预装该系统的 32GB 启动 U 盘。它起初适配 Windows 8 企业版,后续拓展支持 Windows 8.1 及 Windows 10 的企业版、教育版,Windows 10 1607 版本及之后的专业版也纳入适配范围。但是,到了 2019 年 的 Windows 10 1903 版本发布时,微软宣布停止对其开发,2020 年 Windows 10 2004 版本中该功能被正式移除,缘由是它不支持功能更新,且所需的特定类型 USB 设备也逐渐不再被 OEM 厂商支持。不过这个功能确实非常方便,也吸引很多大佬来研究、发展Windows to go。其中最具有代表性的就是萝卜头IT论坛的WTG辅助工具,以及edgeless工具。今天我们暂时不用这两个工具,教大家直接手动在ventoy上部署windows to go!今天我们就来制作一个既能用ventoy,还能启动完整windows的u盘。了解了我们今天的任务,我们现在就可以开始教学了!哦对了,在看完文章后,如果手痒难耐想要实践一把,不要忘记领取文末的关键词哦!
直到我在GitHub这座宝库里,挖到了这个存在了N年、累计下载超3000万次的镇宅神器——Angry IP Scanner。这名字起得就传神,“愤怒”二字,精准表达了咱们面对混沌网络时的那点小情绪。今儿这篇,就带大伙儿盘盘这个Java写的轻量级小工具,看它如何用最直接的方式,帮你一键“理清”网络,让所有连接设备都无所遁形。开源、免费、跨平台,堪称网络界的“户籍警察”,绝对是管家和维护人员的必备神器。走起,扫描!
在GitHub上有一个存在了好多年的开源项目——Angry IP Scanner,就是为了解决这个问题而生的。这个用Java编写的小工具,凭借其简单直接的设计,已经成为世界各地许多网络管理员甚至好奇用户的必备神器,累计下载量超过了2300万次,最近它刚刚发布了3.9.3版本。
在瞬息万变的互联网时代,你是否曾经历过这样的场景:精心收藏的网页链接,几天后却变成了冰冷的”404 Not Found”;那份至关重要的研究资料,在你最需要时却显示”内容已被删除”。在信息爆炸却又转瞬即逝的数字海洋中,我们每天都在面临宝贵内容消失的风险。ArchiveBox作为一款开源的自托管网页归档工具,正是为解决这一痛点而生。它能够将任何有价值的网页完整地保存到本地,包括文字、图片、PDF甚至音视频内容,建立你自己的私人数字图书馆。简单来说,它就像是一个”时光机器”,能够捕捉网页在某一时刻的完整状态,让你在任何时候都能重新访问当时的内容。
以前经常用 Internet Archive 来保存网页内容,但也有不少问题,存下来的页面内容经常缺东少西,视频播放不了,图片加载不出来。