欢迎使用 WordPress。这是您的第一篇文章。编辑或删除它,然后开始写作吧!
博客
-
薅秃 Hugging Face!0 元白嫖 Ubuntu 服务器,玩法太多小心被风控😂
现在云服务器价格贵到肉疼,学生党、打工人想整个专属服务器搞开发、搭网站,钱包直接劝退?nonono!今天给你们解锁一个神仙操作 ——Hugging Face Spaces 免费额度,不用信用卡、不用实名,反手就能掏出一个完整 Ubuntu 系统,从 JupyterLab 玩到 Web 服务,甚至能搞桌面环境,堪称 “免费资源界的隐藏大佬”!不过友情提示:别玩太疯,不然平台可能把你 “请出会场” 哦~
Leepoet先给大家划重点:这波羊毛真・无套路!
- 不用绑卡!不用实名!注册 Hugging Face 账号就行(官网点几下就搞定)
- 不用额外硬件!一台能上网的电脑 / 手机,全程在线操作
- 免费版 CPU 够打!轻量开发、小型网站、学习测试完全 hold 住
话不多说直接实操。
新建一个spaces

这里选择jupyterlab

jupyterlab只可以选择private,jupyter_taken设置,这里随便设置一个自己方便记忆的taken就好,例:666666

选择完后直接create space,直接下面的流程,进入自动building流程,大概需要等3分钟左右,选择jupyterlab的好处是因为它会直接装Ubuntu20.04系统,方便

可以看到红框内都是预装的服务

安装完后,输入jupyter taken

进入jupterlab界面,直接点teminal进入终端。

先更新一下软件

安装neofetch查看系统信息


安装宝塔面板Ubuntu/Deepin安装命令:
wget -O install_panel.sh https://download.bt.cn/install/install_panel.sh && sudo bash install_panel.sh ssl251104
安装完后可以看到当前服务器的ip,但是这个IPV4的IP是正常访问不了的,这应该是huggingface禁止的。所以要通过穿透用域名访问服务。

注册并进入ngrok

能过命令安装ngrok进行简单的穿透测试。

安装完后,添加authtoken

添加完后会提示:Authtoken saved to configuration file: /home/user/.config/ngrok/ngrok.yml,然后直接使用ngrok穿透BT的端口

穿透成功

直接访问面板地址

进入后直接安装LNMP套件,这个过程大概在10分钟左右

安装完lnmp套件后,点网站,自定义域名处因为localhost是做不了访问的,所以这里推荐使用“0.0.0.0:端口号或者127.0.0.1:端口号”做为访问路径,部署网站后,可以通过穿透端口绑定域名,所以也不用做过多的设置。
进阶:使用CLOUDFLARE TUNNELS进行穿透,用自定义域名绑定服务端口,实现服务自由,打开
https://one.dash.cloudflare.com,网络-连接器-添加隧道


自定义一个隧道名

因为是ubuntu系统,它做为debian的儿子,这里必然选debian

回到jupterlab,+号,新建一个launcher进入一个新的terminal窗口

提权后输入cloudflare的隧道安装命令

安装完后,继续输入自动运行隧道命令


安装成功后,回到https://one.dash.cloudflare.com/面板,可以看到状态是已连接了,然后下一步

设置穿透的端口,这里用bt的端口34386进行穿透到bt.19901117.xyz。(*注:首先要先把自己的自定义域名先托管到cloudflare)

设置完后,可以看到状态是正常。

更多设置,和自定义服务点右侧三个小点,进行配置


CF穿透成功。

安装ubuntu-desktop
先更新软件到最新
sudo apt update && sudo apt upgrade -y
安装桌面环境
sudo apt install ubuntu-desktop
测试安装XRDP
sudo apt install xrdp -y
查看一下是否安装成功以及xrdp的端口:sudo nano /etc/xrdp/xrdp.ini

看下能不能通过CF穿出来,因为3389端口走的是TCP协议,所以


好吧 ,没穿出来

结果没穿出来,还风控了0 0


但算是一种尝试吧,无论如何目前来讲Hugging Face 不仅是 AI 开发者的天堂,还是白嫖党的宝藏!从开发环境到 Web 服务,再到桌面系统,只要敢想,就能用免费额度实现~ 不管是学生党学 Linux、开发者测项目,还是搭个人小网站,这波羊毛都值得冲!先这样吧,还有一些玩法还在探索中,不过正因为有terminal又是ubuntu的系统,所以玩法还是很多的,很多git,nodejs项目都可以拉取部署后,通过服务端口穿透出来,原理都差不多。
不过记住:适度薅羊毛,平台才能长期提供免费资源~ 大家还有什么新奇玩法,欢迎在评论区分享,一起把免费服务器玩出花!
Tags: Hugging Face 白嫖服务器 免费云服务 Ubuntu 部署 宝塔面板 穿透教程 开发神器
-

告别天价软件!开源数字人项目,让你轻松打造专属虚拟分身
是否曾对炫酷的数字人技术心动,却被高昂的成本和陡峭的学习曲线劝退?无论是想成为虚拟主播,还是开发AI助手,今天这篇文章将是你的终极入门指南。我精选了5个GitHub上高星的开源项目,覆盖从人脸生成、实时驱动到智能对话的全流程,帮你零成本开启数字人创作之旅!
为何要关注开源数字人项目?
数字人已广泛应用于虚拟主播、数字员工、AI客服等领域,但商业解决方案往往价格不菲。开源项目则打破了这一壁垒,将顶尖技术免费开放给所有开发者与创作者。你无需从零开始,即可基于成熟框架快速定制专属虚拟形象,真正实现“数字人自由”。
项目名 核心优势 适用人群 技术门槛 部署难度 最佳场景 Face-Transformers 2D人脸生成,风格多样 头像设计、新手 低 中 虚拟头像制作、数字分身设计 Live2D Cubism SDK 2D实时驱动,直播适配好 虚拟主播、UP主 中 易 2D虚拟直播、短视频出镜 Avatarify 实时变身,会议神器 打工人、社恐 低 易 视频会议虚拟形象 ChatGPT-4V Digital Human 智能对话,语音交互 开发者、内容党 中 中 智能客服、虚拟助手 PIFuHD 3D建模,单图生成 3D创作者 中高 中高 3D虚拟偶像、游戏角色建模 1. Face-Transformers:数字人脸“生成大师”
介绍:小白也能上手的人脸生成工具!基于AI模型生成超逼真数字人脸,支持自定义性别、年龄、发型,还能让人脸“动起来”,做虚拟头像超方便。
主要功能:- 生成高清数字人脸图片,支持风格迁移(如写实、动漫、油画风)
- 调整人脸特征:改发型、换表情、加配饰,自由度超高
- 导出人脸模型用于视频制作或游戏角色
应用场景:做虚拟主播头像、设计游戏NPC脸模、生成个性化数字分身
部署方法:
- 克隆仓库:
git clone https://github.com/hukkelas/Face-Transformers.git - 安装依赖:
pip install -r requirements.txt - 运行Web界面:
python app.py,在浏览器调参数生成人脸
亮点&小槽点:生成效果逼真,操作可视化;但需要显卡支持,低配电脑可能跑不动。
GitHub链接:https://github.com/hukkelas/Face-Transformers
2. Live2D Cubism SDK:2D数字人“动效引擎”
介绍:虚拟主播圈的“顶流工具”!专门做2D数字人实时驱动,给静态头像加表情、动嘴巴、摆姿势,直播间互动感拉满。
主要功能:- 绑定人脸关键点,通过摄像头实时驱动数字人表情(眨眼、微笑、张嘴)
- 支持手动调动作:点头、挥手、比心等预设动作库
- 导出动画视频或实时推流到直播平台
应用场景:2D虚拟主播直播、短视频数字人出镜、线上课程虚拟讲师
部署方法:
- 克隆仓库:
git clone https://github.com/Live2D/CubismSDK.git - 下载官方示例模型(需注册账号)
- 运行示例程序:
./Samples/BasicExample,用摄像头驱动模型
亮点&小槽点:2D动效自然,直播适配好;但高级功能需付费授权,免费版够用基础需求。
GitHub链接:https://github.com/Live2D/CubismSDK
3. Avatarify:实时数字人“变身神器”
介绍:打工人狂喜的视频会议神器!通过摄像头把自己实时变成数字人,开会不想露脸?用虚拟分身代替,还能换发型妆容。
主要功能:- 实时人脸追踪,把摄像头画面替换成数字人形象
- 支持自定义数字人:上传照片生成专属分身,保留你的表情特征
- 兼容Zoom、Teams等会议软件,即插即用
应用场景:视频会议虚拟形象、线上讲座匿名出镜、直播时切换数字人身份
部署方法:
- 克隆仓库:
git clone https://github.com/alievk/avatarify.git - 安装依赖:
conda env create -f environment.yml - 启动程序:
python avatarify.py,选择数字人模型即可使用
亮点&小槽点:实时性强,操作简单;但对网络和电脑性能有要求,可能偶尔卡顿。
GitHub链接:https://github.com/alievk/avatarify.git
4. ChatGPT-4V Digital Human:会聊天的“智能数字人”
介绍:能说会道的数字助手框架!把ChatGPT的大脑装进数字人,支持语音对话、图像识别,问问题、讲故事、查信息样样行。
主要功能:- 语音交互:说话就能和数字人聊天,支持多语言
- 视觉能力:数字人能“看”图片,描述内容或回答相关问题
- 自定义人设:设置数字人性格、语气、专业领域(如客服、老师)
应用场景:做智能客服数字人、开发虚拟助手、给孩子做AI玩伴
部署方法:
- 克隆仓库:
git clone https://github.com/yangjianxin1/ChatGPT-4V-Digital-Human.git - 配置OpenAI API密钥:修改
config.py - 运行:
python app.py,通过麦克风和数字人对话
亮点&小槽点:对话自然,功能全面;但需要OpenAI API密钥,有使用成本。
GitHub链接:https://github.com/yangjianxin1/ChatGPT-4V-Digital-Human
5. PIFuHD:3D数字人“建模神器”
介绍:3D建模小白的救星!上传一张照片就能生成完整3D数字人模型,带身体、穿衣服,还能摆各种姿势,做虚拟偶像超合适。
主要功能:- 单张照片生成高精细3D数字人,包括面部、身体、服装细节
- 支持调整姿势:让数字人站、坐、挥手,动作自然
- 导出3D模型文件,用于动画制作或游戏开发
应用场景:3D虚拟偶像制作、元宇宙数字分身、游戏角色快速建模
部署方法:
- 克隆仓库:
git clone https://github.com/facebookresearch/pifuhd.git - 安装依赖:
pip install -r requirements.txt - 运行:
python -m apps.simple_test --input_image path/to/your/photo.jpg
亮点&小槽点:3D建模效果惊艳,单图生成超方便;但模型训练需要大显存,普通电脑跑起来慢。
GitHub链接:https://github.com/facebookresearch/pifuhd
-

GitHub热门智能体开源项目,让你秒变AI大神!
AI发烧友们,大家好!最近是不是感觉哪里都在谈“智能体(Agent)”?从自动编程到智能决策,它俨然成了AI界的新晋“顶流”。但面对海量信息,你是否也曾感到无从下手:教程太浅、门槛太高,想亲手实践却找不到合适的项目?别担心!今天,我们就为大家精选了GitHub上10个高星智能体开源项目,涵盖从通用框架到垂直工具,从单机作战到多体协同,并附上保姆级介绍与实战指南。收藏这篇文章,你的智能体学习之路将事半功倍!
智能体是什么?为什么它值得关注?
简单来说,智能体是一个“会独立思考、自主行动的AI助手”。你只需给定一个目标,它便能自主规划任务、调用工具、执行步骤,甚至与其他智能体协同完成复杂工作。目前,智能体已广泛应用于科研、办公、游戏开发等领域。而开源项目,正是我们快速入门的“捷径”——无需从零造轮子,基于成熟代码稍作修改,你就能打造属于自己的智能体,高效又实用!
先唠两句:啥是智能体?为啥要学?
说白了,智能体就是“能自己干活的AI助手”——给它个目标,它会自己拆解任务、调用工具、调整策略,甚至和其他AI“组队打工”。现在从科研、办公到游戏、机器人,到处都能看到它的身影。而开源项目就是咱普通人的“快车道”:不用从零造轮子,直接改改代码就能搭自己的智能体,香到不行!
10个必玩智能体开源项目,按头安利!
1. AutoGPT:智能体界的“开山网红”
介绍:当年一句“AI自主完成任务”直接引爆GitHub的狠角色!基于GPT模型,能自己规划、搜索、执行任务,堪称“AI版自动化脚本”。
10个项目横向对比表(选项目不纠结!)
项目名 核心优势 适用人群 技术门槛 部署难度 最佳场景 AutoGPT 入门简单,自主性强 新手、小白 低 易 简单任务自动化 MetaGPT 分工清晰,输出质量高 开发者、产品 中 中 软件开发、项目规划 LangChain 万能工具箱,兼容性强 全阶段开发者 中 易 自定义智能体开发 AutoGen 多智能体协作,微软背书 进阶开发者 中高 中 复杂决策、团队协作 BabyAGI 代码极简,原理清晰 学习者、新手 低 易 理解智能体逻辑 HuggingGPT 多模型联合,成本低 开发者、研究者 中高 中高 多模态任务、本地部署 AgentGPT 零代码,网页直接用 纯新手、体验党 无 无 快速测试、简单任务 GPT-Researcher 学术向专业,文献整理 学生、研究员 低 易 论文写作、文献综述 CrewAI 团队管理逻辑强 项目管理者 中 中 多角色协作、复杂任务 AgentQL 自然语言查数据 业务、数据岗 低 易 数据分析、报表生成
主要功能:- 自主拆解复杂任务(比如“写一篇AI发展报告”→ 拆成查资料、整理数据、写初稿、润色)
- 调用搜索引擎、文件工具,甚至控制其他软件
- 支持自定义目标和规则,灵活性拉满
应用场景:自动写报告、数据整理、批量处理文件、简单的科研辅助
部署方法:- 克隆仓库:
git clone https://github.com/Significant-Gravitas/AutoGPT.git - 安装依赖:
pip install -r requirements.txt - 配置OpenAI API密钥和目标,运行
python -m autogpt即可
亮点&小槽点:入门简单,适合新手练手;但偶尔会“钻牛角尖”,需要手动干预调整目标。
GitHub链接:https://github.com/Significant-Gravitas/AutoGPT
2. MetaGPT:多智能体“职场协作”神器
介绍:由国内团队开发的“全流程智能体框架”,核心是模拟“职场团队分工”——比如产品经理、开发、测试各司其职,合力完成项目。
主要功能:- 内置“角色分工”系统:支持产品经理(提需求)、架构师(画方案)、开发(写代码)等角色
- 自动生成文档、代码、测试用例,甚至能输出项目计划
- 多智能体实时沟通协作,像真人团队一样推进任务
应用场景:小型软件开发、项目规划、团队协作流程模拟、创业项目原型设计
部署方法:
- 克隆仓库:
git clone https://github.com/geekan/MetaGPT.git - 安装依赖:
pip install -r requirements.txt - 配置API密钥,输入需求(比如“开发一个贪吃蛇游戏”),运行
python startup.py "你的需求"
亮点&小槽点:分工超清晰,输出质量高;但对硬件和API额度要求稍高,新手可能需要先调参。
GitHub链接:https://github.com/geekan/MetaGPT
3. LangChain:智能体的“工具箱”(必学!)
介绍:虽然不算纯智能体,但绝对是构建智能体的“基础设施”!把各种AI模型、工具、数据串起来,让你轻松搭出复杂智能体。
主要功能:- 集成主流大模型(GPT、LLaMA、文心一言等)和工具(搜索、数据库、API调用)
- 提供“记忆模块”:让智能体记住对话历史和任务状态
- 支持“链(Chain)”和“智能体(Agent)”两种模式,灵活组合功能
应用场景:自定义智能体开发、聊天机器人、知识库问答、数据分析助手
部署方法:
- 直接安装库:
pip install langchain - 搭配具体模型(如OpenAI):
pip install openai - 参考文档写代码:定义工具→设置智能体→调用执行
亮点&小槽点:兼容性超强,几乎所有智能体项目都绕不开它;但需要点代码基础,纯小白可能要先补Python。
GitHub链接:https://github.com/langchain-ai/langchain
4. AutoGen:微软出品的“智能体协作平台”
介绍:微软研究院开源的多智能体框架,主打“让多个AI智能体聊天协作”,甚至能和人类实时互动,解决复杂问题。
主要功能:- 支持“智能体-智能体”“智能体-人类”混合协作
- 自动分配任务、调用工具,还能辩论优化方案(比如两个智能体吵架改代码哈哈)
- 兼容多种大模型,支持本地部署(不用依赖OpenAI)
应用场景:复杂决策、代码审查、学术研究协作、多人任务分配
部署方法:
- 安装:
pip install pyautogen - 写配置文件:定义智能体角色、模型、工具权限
- 启动对话:
python your_script.py让智能体们开始“打工”
亮点&小槽点:微软背书,稳定性强;协作逻辑超灵活,但配置稍复杂,建议先看官方示例。
GitHub链接:https://github.com/microsoft/autogen
5. BabyAGI:极简任务智能体
介绍:名字萌但功能硬核!用不到200行代码实现“目标-任务-执行”闭环,适合新手理解智能体核心逻辑。
主要功能:- 核心逻辑:设定目标→生成任务→执行任务→更新任务列表
- 支持用向量数据库存储任务记忆,避免重复劳动
- 可自定义执行工具(比如加个网页爬虫、计算器)
应用场景:学习智能体原理、搭建轻量任务助手(如定时查天气、整理邮件)
部署方法:
- 克隆仓库:
git clone https://github.com/yoheinakajima/babyagi.git - 安装依赖:
pip install -r requirements.txt - 配置OpenAI和向量数据库密钥,运行
python babyagi.py输入目标
亮点&小槽点:代码极简,新手能看懂;但功能基础,复杂任务需要自己加工具。
GitHub链接:https://github.com/yoheinakajima/babyagi.git
6. HuggingGPT: Hugging Face+GPT的“强强联合”
介绍:浙大团队开源的“大模型调度官”!让GPT当“指挥官”,调用Hugging Face上的1000+开源模型干活,成本低还强。
主要功能:- GPT负责拆解任务、选模型,Hugging Face模型负责具体执行(如图像识别、翻译、代码生成)
- 支持文本、图像、语音等多模态任务,全能选手
- 本地部署可选,不用完全依赖API
应用场景:多模态任务处理(如“给图片写文案+翻译”)、低成本智能体开发
部署方法:
- 克隆仓库:
git clone https://github.com/microsoft/HuggingGPT.git - 安装依赖:
pip install -r requirements.txt - 配置OpenAI和Hugging Face密钥,运行示例脚本
亮点&小槽点:模型资源丰富,成本可控;但对设备算力有要求,本地跑大模型可能卡。
GitHub链接:https://github.com/microsoft/HuggingGPT
7. AgentGPT:浏览器直接玩的“零代码智能体”
介绍:懒人福音!不用装环境,打开网页就能创建智能体,输入目标直接跑,新手友好度拉满。
主要功能:- 网页端可视化操作,填个目标就能启动智能体
- 实时显示任务拆解和执行过程,像“看AI打工直播”
- 支持保存历史记录,随时复盘调整
应用场景:快速测试智能体效果、新手入门体验、简单任务自动化(如写提纲、查信息)
部署方法:
- 直接用在线版:https://agentgpt.reworkd.ai/(偶尔需要排队)
- 本地部署:克隆仓库后按文档配置Next.js环境,启动即可
亮点&小槽点:零代码门槛,谁都能玩;但功能有限,复杂任务还是得用本地项目。
GitHub链接:https://github.com/reworkd/AgentGPT
8. GPT-Researcher:学术党狂喜的“论文助手”
介绍:专注“学术研究”的智能体!输入研究主题,自动搜文献、读论文、整理观点,还能生成带引用的报告。
主要功能:- 自动搜索学术数据库(Google Scholar、Arxiv等)和权威来源
- 提取核心观点、对比不同研究,生成结构化报告(带参考文献格式)
- 支持自定义研究深度和报告风格(如摘要、综述、批判性分析)
应用场景:写论文查资料、文献综述、快速了解研究领域进展
部署方法:
- 克隆仓库:
git clone https://github.com/assafelovic/gpt-researcher.git - 安装依赖:
pip install -r requirements.txt - 配置API密钥,运行
python main.py输入研究主题
亮点&小槽点:学术向超专业,省超多查文献时间;但依赖英文资源,中文文献支持一般。
GitHub链接:https://github.com/assafelovic/gpt-researcher
9. CrewAI:多智能体“团队管理”框架
介绍:把智能体变成“团队成员”,你当“老板”给任务,它自动分配角色、设目标、追进度,主打一个省心。
主要功能:- 可视化定义角色(如“市场分析师”“文案写手”)、技能和目标
- 智能体间自动沟通协作,遇到问题会“请示”你
- 支持集成各种工具(API、数据库、爬虫)扩展能力
应用场景:内容创作团队、市场调研、项目管理、多步骤任务处理
部署方法:
- 安装库:
pip install crewai - 写代码定义角色、任务和工具
- 启动团队:
crew.kickoff()坐等结果
亮点&小槽点:团队管理逻辑超清晰,适合复杂协作;但文档较少,新手可能需要多试。
GitHub链接:https://github.com/joaomdmoura/crewai
10. AgentQL:智能体+数据库的“数据查询神器”
介绍:让智能体直接“懂数据库”!输入自然语言问题(比如“查下上月销售额前5的产品”),自动生成SQL并查结果。
主要功能:- 自然语言转SQL,不用学代码也能查数据库
- 支持MySQL、PostgreSQL等主流数据库,兼容性强
- 自动校验SQL正确性,避免查错数据
应用场景:数据分析、业务报表生成、非技术人员查数据
部署方法:
- 安装:
pip install agentql - 连接数据库,配置API密钥
- 用自然语言提问:
agent.query("你的问题")
亮点&小槽点:数据查询超方便,非技术党狂喜;但复杂查询可能需要手动调整SQL。
GitHub链接:https://github.com/AgentQL/agentql
-
AI开源项目推荐清单赶紧收藏,开启你的开源AI宝藏库!
在AI技术日新月异的今天,你是否也曾面临这些困惑:强大的模型总是闭源收费?想动手实践却不知从何开始?工具繁多却难以找到真正高效可靠的选项?本文正是为你量身打造的“寻宝图”。我们深入GitHub,为你精挑细选了10个涵盖不同领域的顶级开源AI项目。
10个必收藏的AI开源项目 | GitHub高星推荐 | 大模型/图像生成/语音识别/目标检测
从驱动对话的大语言模型(LLaMA),到创造视觉奇迹的图像生成器(Stable Diffusion);从精准的语音识别工具(Whisper),到实时目标检测系统(YOLOv8);乃至帮助你快速构建应用的开发框架(LangChain, Gradio)——每一款都经过社区验证,兼具创新性与实用性。无论你是开发者、研究者、学生还是技术爱好者,这份清单都将为你提供从学习探索到项目实战的强力支持。现在,就让我们一起解锁这些开源神器,将 cutting-edge 的AI能力,转化为你手中的利刃。
不管你是想练手、做项目,还是直接薅来干活,这篇清单都能让你直呼“捡到宝”!话不多说,上硬菜~
1. LLaMA:Meta家的“平民大模型”
详细介绍:这是Meta(脸书母公司)开源的大语言模型家族,从70亿参数到700亿参数应有尽有,主打一个“轻量能跑、开源免费”。普通人下载后,在消费级显卡上就能微调,不用再眼巴巴看着大厂模型流口水~
核心特点:
- 尺寸灵活:从7B到70B参数,电脑配置不够也能玩小规格;
- 微调友好:社区有超多现成工具(比如Alpaca-LoRA),新手也能快速调教;
- 多语言支持:对中文、英文等主流语言适配都不错。
应用场景:做聊天机器人、个性化问答系统、内容生成工具,甚至训练垂直领域小模型(比如法律、医疗)都合适。
项目对比:和闭源的GPT-4比,LLaMA胜在“免费开源”,普通人也能下载微调;但论综合能力,GPT-4还是老大哥。和其他开源大模型(比如Mistral)比,LLaMA的生态更成熟,社区工具多到用不完~
GitHub地址:https://github.com/facebookresearch/llama
2. Stable Diffusion:AI绘画界的“扛把子”
详细介绍:提到AI画图,没人能绕开Stable Diffusion!由Stability AI开源,支持文本生成图像、图像修复、风格迁移,关键是完全免费商用(非商用更没问题),普通电脑装个WebUI就能玩到飞起。

核心特点:
- 插件狂魔:千种风格模型、LoRA微调、ControlNet控图,玩法多到离谱;
- 本地化部署:不用蹭在线接口,自己电脑就能生成,隐私性拉满;
- 社区活跃:每天都有新模型、新教程,小白也能快速出“大作”。

应用场景:设计插画、海报制作、游戏美术辅助、表情包生成,甚至修复老照片、给线稿上色都超好用。


项目对比:和Midjourney比,Stable Diffusion胜在“免费开源+本地化”,但出图效率和精细度稍弱;和DALL-E比,它的可控性更强,插件生态甩对手十条街~
GitHub地址:https://github.com/Stability-AI/stablediffusion
3. Whisper:OpenAI的“语音魔术师”
详细介绍:OpenAI开源的语音识别模型,能把语音转文字、文字转语音,还支持99种语言!关键是准确率超高,连带口音的中文、英文都能轻松识别,简直是会议记录、视频字幕的救星。

核心特点:
- 多任务全能:语音转文字、文字转语音、翻译(比如日语语音直接转中文文字)全拿下;
- 小模型也能打:哪怕用base(基础)模型,准确率也甩很多商用工具一条街;
- 开箱即用:Python几行代码就能调用,不用复杂配置。
应用场景:会议纪要自动生成、视频字幕批量制作、播客转文字、多语言语音翻译工具开发。
项目对比:和百度语音API比,Whisper胜在“本地部署+免费”,但实时性稍弱;和Google Speech-to-Text比,它对小语种和口音的兼容性更好~
GitHub地址:https://github.com/openai/whisper
4. LangChain:LLM应用的“胶水框架”
详细介绍:想把大模型和数据库、API、知识库结合起来?LangChain就是干这个的!它像“乐高积木”一样,把各种AI组件拼起来,让你轻松开发聊天机器人、问答系统、智能助手,不用从零写代码。

核心特点:
- 组件丰富:支持连接各种大模型(GPT、LLaMA、Claude)、数据库(MySQL、MongoDB)、搜索引擎;
- 流程可控:能设计AI的思考步骤(比如“先查资料再回答”),避免大模型“瞎编”;
- 入门简单:文档超详细,跟着教程走,半小时就能搭个简单的问答工具。
应用场景:开发企业知识库问答机器人、带记忆功能的聊天助手、基于私有数据的AI分析工具。
项目对比:和同类框架LlamaIndex比,LangChain更侧重“流程编排”,适合复杂应用;LlamaIndex则强在“数据处理”,新手入门可能更简单~
GitHub地址:https://github.com/langchain-ai/langchain
5. YOLOv8:目标检测界的“闪电侠”
详细介绍:YOLO系列的最新版,主打“又快又准”的目标检测。能瞬间识别图片/视频里的人、车、动物、物体,在普通显卡上就能实时处理视频流,工业级场景都在用它。

核心特点:
- 速度狂魔:每秒能处理几十帧视频,监控摄像头实时分析毫无压力;
- 轻量化:小模型能在手机、嵌入式设备上跑,大模型精度堪比专业工具;
- 开箱即用:预训练模型直接丢图就能识别,微调自己的数据也超简单。
应用场景:智能监控(比如识别异常行为)、自动驾驶辅助(识别行人车辆)、工业质检(检测产品缺陷)、手机拍照识物APP。
项目对比:和Faster R-CNN比,YOLOv8速度快10倍以上,精度稍低但够用;和SSD比,它的小目标识别能力更强,适合复杂场景~
GitHub地址:https://github.com/ultralytics/ultralytics
6. AutoGPT:AI界的“自律打工人”
详细介绍:让AI自己“思考、规划、执行”的工具!你只需要给它一个目标(比如“写一篇关于AI开源项目的推文”),它会自动查资料、生成大纲、写内容,甚至能调用其他工具,全程不用你插手。
核心特点:
- 自主决策:不用一步步指挥,AI自己拆解任务、调整策略;
- 工具集成:能联网查信息、用搜索引擎、调用API,像个真人助理;
- 开源免费:虽然还在完善中,但基础功能已经能用,适合尝鲜。
应用场景:自动写报告、市场调研分析、内容创作辅助、复杂问题拆解(比如“规划一场AI技术分享会”)。
项目对比:和ChatGPT的“单次对话”比,AutoGPT胜在“多步骤自主执行”,但容易“走偏”;和同类工具BabyAGI比,它的界面更友好,新手更容易上手~
GitHub地址:https://github.com/Significant-Gravitas/AutoGPT
7. Diffusers:AI生成的“工具箱”
详细介绍:Hugging Face开源的生成模型库,里面不仅有Stable Diffusion的核心代码,还有各种图像生成、音频生成、视频生成模型。相当于给开发者搭了个“AI生成工厂”,想调参、改模型?用它就对了。

核心特点:
- 模型丰富:除了图像生成,还有文生视频(如Video Diffusion)、图像修复等模型;
- 代码简洁:几行代码就能调用复杂模型,调参改配置超方便;
- 和Hugging Face生态无缝衔接:能直接用Hub上的模型,不用自己下载。
应用场景:开发自定义AI绘画工具、研究生成模型原理、二次开发生成模型(比如加新功能)。
项目对比:和Stable Diffusion的WebUI比,Diffusers更适合“开发者”做二次开发;WebUI则适合“普通用户”直接用~
GitHub地址:https://github.com/huggingface/diffusers
8. FastChat:大模型的“聊天服务员”
详细介绍:想给你的LLaMA、Mistral等开源大模型加个聊天界面?FastChat一键搞定!它支持多模型部署、对话历史管理、API调用,还能搭个网页版聊天框,小白也能快速拥有自己的“ChatGPT”。
核心特点:
- 多模型兼容:主流开源大模型都能装,切换模型像换手机壁纸一样简单;
- 部署方便:一条命令启动服务,网页端、API端同时可用;
- 支持多用户:能当服务器让多人同时用,适合小团队共享。
应用场景:搭建私有聊天机器人、测试开源大模型效果、给模型加个可视化界面方便演示。
项目对比:和同类工具vLLM比,FastChat更侧重“聊天交互”,界面更友好;vLLM则强在“高并发部署”,适合大规模使用~
GitHub地址:https://github.com/lm-sys/FastChat
9. MONAI:医疗AI的“专业助手”
详细介绍:专门为医疗影像AI开发的框架,基于PyTorch,集成了各种医学图像预处理、分割、分类工具。医生和开发者用它能快速开发肿瘤检测、器官分割等模型,不用再从零处理DICOM这类特殊格式。

核心特点:
- 医疗专用:支持DICOM格式、3D影像处理(CT/MRI常用),贴合医疗场景;
- 模型丰富:内置肿瘤分割、病灶检测等预训练模型,开箱即用;
- 合规友好:遵循医疗数据隐私规范,适合医院、科研机构使用。
应用场景:医学影像辅助诊断(比如CT肺结节检测)、病灶分割、医疗图像分析研究。
项目对比:和普通CV框架(如PyTorch Lightning)比,MONAI胜在“医疗专用工具多”,不用自己写医学图像预处理代码~
GitHub地址:https://github.com/Project-MONAI/MONAI
10. Gradio:AI模型的“快速装裱师”
详细介绍:开发者的“界面救星”!不用学前端,几行Python代码就能给你的AI模型(不管是图像生成、语音识别还是分类模型)加个网页交互界面,支持上传图片、输入文字、实时显示结果,演示、测试超方便。

核心特点:
- 代码极简:哪怕只会写print,也能搭出能用的界面;
- 实时更新:改代码不用重启服务,刷新网页就能看效果;
- 支持多类型输入输出:文字、图片、音频、视频都能搞定。
应用场景:快速演示AI模型效果、给客户/老板展示项目、收集用户反馈、教学中的模型可视化。
项目对比:和Streamlit比,Gradio更侧重“快速交互”,界面组件更丰富;Streamlit则强在“数据可视化”,适合展示分析结果~
GitHub地址:https://github.com/gradio-app/gradio
以上10个AI开源项目,从大模型、绘画、语音到开发工具,基本覆盖了当下最火的AI应用场景。
-
ComfyUI-HYPIR节点:LeePoet力推基于SD2.1图像超清修复放大
我是LeePoet。今天给大家推荐一款我最近深度体验的ComfyUI节点——ComfyUI-HYPIR,这是一个基于HYPIR项目开发的图像修复工具,专门针对SD2.1模型进行了优化,能够实现高质量的图像修复和超分辨率放大。该技术基于扩散模型生成的分数先验进行图像修复与放大,具有高质量、清晰、锐利的效果。
💡 为什么选择HYPIR?
HYPIR(Harnessing Diffusion-Yielded Score Priors for Image Restoration)是一个利用扩散模型得分先验进行图像修复的先进技术。相比传统的ESRGAN放大方式,HYPIR在细节保留和伪影控制方面表现更出色,特别适合处理模糊、噪点严重的图像。
🎯 适用场景
ComfyUI-HYPIR几乎覆盖了所有图像修复需求:
- 老照片修复:将模糊的老照片恢复到高清状态
- 商品图优化:电商产品图放大后依然保持清晰细节
- 动漫/游戏素材:二次元图片放大后线条清晰,色彩饱满
- 人像写真:针对人像照片进行专项优化,面部细节更自然
- 风景照片:自然风光放大后远景细节依然丰富
HYPIR可在GitHub上找到,推荐使用其ComfyUI插件实现,模型需下载并放置于ComfyUI的models文件夹中。操作流程包括单张图片上传、设置放大倍数(支持1-8倍,推荐2-4倍),并通过HYPIR Advanced节点进行处理。放大前后对比,HYPIR在不改变原图结构的前提下显著提升清晰度。此外,支持批量处理,通过设置路径和数量实现多图自动放大。参数方面,coeff值(默认100,可调至500)影响修复强度,数值越高重绘幅度越大,适用于AI生成图像的增强处理。整体流程稳定、操作简便,建议替代旧有放大方法。

开源地址:https://github.com/11dogzi/Comfyui-HYPIR
这是一个用于 HYPIR(利用扩散得分先验进行图像修复) 的 ComfyUI 插件,HYPIR 是基于 Stable Diffusion 2.1 的先进图像修复模型。
功能特性
- 图像修复:利用扩散先验修复和增强低质量图像
- 批量处理:一次处理多张图片
- 高级控制:可微调模型参数以获得最佳效果
- 模型管理:高效加载和复用 HYPIR 模型
- 放大功能:内置放大功能(1x 到 8x)
安装方法
1. 安装插件
将本文件夹放入 ComfyUI 的
custom_nodes目录下:ComfyUI/custom_nodes/Comfyui-HYPIR/2. 安装 HYPIR 依赖
进入 HYPIR 文件夹并安装所需依赖:
cd ComfyUI/custom_nodes/Comfyui-HYPIR/HYPIR pip install -r requirements.txt
3. 模型下载(自动)
HYPIR 模型
修复模型将下载到:ComfyUI/models/HYPIR/HYPIR_sd2.pth
基础模型(Stable Diffusion 2.1)
基础 Stable Diffusion 2.1 模型将在需要时自动下载到:ComfyUI/models/HYPIR/stable-diffusion-2-1-base/
手动下载(可选):
HYPIR 模型:如果你希望手动下载,可以从以下地址获取 HYPIR 模型:
- HuggingFace: HYPIR_sd2.pth
- OpenXLab: HYPIR_sd2.pth
请将
HYPIR_sd2.pth文件放在以下任一位置:- 插件目录:
ComfyUI/custom_nodes/Comfyui-HYPIR/ - ComfyUI 模型目录:
ComfyUI/models/checkpoints/ - 或让插件自动管理,放在
ComfyUI/models/HYPIR/
基础模型: 基础 Stable Diffusion 2.1 模型可从以下地址手动下载:
- HuggingFace:stable-diffusion-2-1-base
请将基础模型放在:ComfyUI/models/HYPIR/stable-diffusion-2-1-base/
注意: 插件会优先在 HYPIR 目录下查找基础模型,如未找到会自动从 HuggingFace 下载。
使用方法
高级图像修复
- 添加 HYPIR Advanced Restoration 节点
- 此节点提供更多参数控制:
model_t:模型步数(默认200)coeff_t:系数步数(默认200)lora_rank:LoRA 阶数(默认256)patch_size:处理块大小(默认512)
配置
你可以在
hypir_config.py中修改默认设置:HYPIR_CONFIG = { "default_weight_path": "HYPIR_sd2.pth", "default_base_model_path": "stable-diffusion-2-1-base", "available_base_models": ["stable-diffusion-2-1-base"], "model_t": 200, "coeff_t": 200, "lora_rank": 256, # ... more settings }模型路径管理
插件包含智能模型路径管理:
- HYPIR 模型:自动下载到
ComfyUI/models/HYPIR/HYPIR_sd2.pth - 基础模型:需要时自动下载到
ComfyUI/models/HYPIR/stable-diffusion-2-1-base/ - 本地优先:插件会优先查找本地模型
- 自动下载:仅在本地未找到模型时才下载
最佳效果小贴士
- 提示词:使用与图片内容相符的描述性提示词
- 人像:”high quality portrait, detailed face, sharp features”
- 风景:”high quality landscape, detailed scenery, sharp focus”
- 通用:”high quality, detailed, sharp, clear”
- 放大:
- 1x 表示仅修复不放大
- 2x-4x 适合中等放大
- 8x 为最大放大(速度较慢)
- 参数:
model_t越高(200-500)修复越强coeff_t越高(200-500)增强越明显lora_rank越高(256-512)质量越好(占用更多内存)
- 内存管理:
- 如遇内存不足可用较小的
patch_size(256-512) - 分批处理图片
- 使用模型加载器节点避免重复加载模型
- 如遇内存不足可用较小的
配置
你可以在
hypir_config.py中修改默认设置:HYPIR_CONFIG = { "default_weight_path": "HYPIR_sd2.pth", "default_base_model_path": "stable-diffusion-2-1-base", "available_base_models": ["stable-diffusion-2-1-base"], "model_t": 200, "coeff_t": 200, "lora_rank": 256, # ... more settings }模型路径管理
The plugin includes intelligent model path management: 插件包含智能模型路径管理:
- HYPIR Model: Automatically downloaded to
ComfyUI/models/HYPIR/HYPIR_sd2.pth - HYPIR 模型:自动下载到
ComfyUI/models/HYPIR/HYPIR_sd2.pth - Base Model: Automatically downloaded to
ComfyUI/models/HYPIR/stable-diffusion-2-1-base/when needed - 基础模型:需要时自动下载到
ComfyUI/models/HYPIR/stable-diffusion-2-1-base/ - Local Priority: The plugin checks for local models first before downloading
- 本地优先:插件会优先查找本地模型
- Automatic Download: Only downloads when models are not found locally
- 自动下载:仅在本地未找到模型时才下载
最佳效果小贴士
使用模型加载器节点避免重复加载模型
提示词:使用与图片内容相符的描述性提示词
人像:”high quality portrait, detailed face, sharp features”
风景:”high quality landscape, detailed scenery, sharp focus”
通用:”high quality, detailed, sharp, clear”
放大:
1x 表示仅修复不放大
2x-4x 适合中等放大
8x 为最大放大(速度较慢)
参数:
model_t越高(200-500)修复越强coeff_t越高(200-500)增强越明显lora_rank越高(256-512)质量越好(占用更多内存)内存管理:
如遇内存不足可用较小的
patch_size(256-512)分批处理图片
常见问题
- 导入错误:请确保已安装 HYPIR 依赖cd HYPIR pip install -r requirements.txt
- 模型未找到:插件会自动下载缺失的模型
- 检查网络连接以便自动下载
- HYPIR 模型:将
HYPIR_sd2.pth放在插件目录或 ComfyUI 模型目录 - 基础模型:将
stable-diffusion-2-1-base文件夹放在ComfyUI/models/HYPIR/ - 插件会自动检查并下载缺失模型
实操:
1.先到https://github.com/11dogzi/Comfyui-HYPIR的仓库直接复制插件仓库地址

2.进入本地的.\ComfyUI\custom_nodes目录,右链git bash拉取仓库

3.启动COMFYUI,通过启动器先拉取HYPIR所需要的库并启动到UI
4.打开huggingface.co,直接使用国内镜像源:https://huggingface.1319lm.top/lxq007/HYPIR/tree/main,复制HYPIR的GIT仓库

5.下载HYPIR修复模型,进入.\ComfyUI\models,右键打开git bash,魔法就使用国内镜像源GIT


6.下载stable-diffusion-2-1-base模型,先进入https://huggingface.1319lm.top/Manojb/stable-diffusion-2-1-base/tree/main,把以下红框框住的都手动下载,因为很多都是重复的一样的模型,只是后缀不一样。我们只需要下一个就行。所以这里不能直接GIT整个仓库。

额外说明:text_encoder、unet、vae都只需要下一个模型即可,如果是FP16的,下载到本地后记得把FP16的字去掉,这样才会被节点识别。


7.下载完所有模型后,重新启动COMFYUI

当然,SD放大的模型与技术有很多,可以说都各有千秋,非要说哪几个最好用,只有等LEEPOET闲来有空再给大家介绍,总而言之ComfyUI-HYPIR是一款功能强大、操作简单的图像修复工具,特别适合需要高质量图像放大的用户。无论是老照片修复、商品图优化还是人像写真处理,都能获得令人满意的效果。如果你正在寻找一款稳定、高效的图像超清修复工具,ComfyUI-HYPIR绝对值得一试。我已经将它作为我的主力图像修复工具,强烈推荐给大家!
相关文章:
ComfyUI-GGUF-VLM 结合 llama.cpp GPU 加速:实现图像反推秒级效率
Custom_Nodes篇:ComfyUI-QwenVL反推节点
Custom_Nodes篇:ComfyUI-QwenVL3-image反推节点
-

淘宝天猫 PC 端 CSS 隐藏技巧:高效实现元素隐形方案
核心实现思路
元素隐藏的核心需求是让目标元素在视觉上不可见,且不影响页面其他元素的正常布局。本次方案通过定位偏移、背景设置与可见性控制的组合方式,既避免了
display: none可能引发的布局塌陷问题,也解决了单纯visibility: hidden占用页面空间的弊端,适配淘宝天猫 PC 端的渲染环境。优化后 CSS 代码
/* 全品类弹窗容器隐藏样式 */ .all-cats-popup { position: absolute; top: -49999px; /* 向上偏移,脱离可视区域 */ left: 0; width: 10000px; height: 100000px; display: block; background: #ffffff; /* 保持背景一致性,避免透明导致的异常显示 */ } /* 弹窗内容区域定位优化 */ .popup-content { position: relative; width: 100%; float: left; clear: both; left: 99999px; /* 向右偏移,进一步确保不可见 */ top: 99490px; height: 100%; background: #ffffff; background-image: url(//gdp.alicdn.com/imgextra/i1/752188877/O1CN013sFHB32FRikpKiLy4_!!75218877.gif); background-position: top center; background-attachment: fixed; background-repeat: no-repeat; } /* 强制显示控制(兼容特殊场景) */ .popup-hidden { visibility: visible; /* 覆盖默认隐藏状态,确保元素可正常渲染 */ }代码解析与使用说明
1. 容器隐藏逻辑
.all-cats-popup类通过position: absolute脱离文档流,再利用超大负值top: -49999px将元素移出页面可视区域。宽高设置为超大值(width: 10000px、height: 100000px)是为了适配不同页面布局,避免元素部分暴露,背景色设置为白色可与页面背景融合,减少视觉冲突。2. 内容区域定位
.popup-content作为子容器,通过float: left和clear: both确保布局不错乱,left和top的超大正值偏移与父容器配合,双重保障元素不可见。背景图相关属性保留了原始需求,适用于需要加载背景资源但不展示元素的场景,background-attachment: fixed可固定背景位置,提升显示一致性。3. 兼容场景控制
.popup-hidden类使用visibility: visible强制元素可见,该类可根据业务需求动态添加或移除,适用于 “默认隐藏,特定条件下显示” 的交互场景,相比display属性切换,visibility不会破坏元素的布局结构,适配淘宝天猫的组件渲染机制。注意事项
- 兼容性适配:该方案兼容主流浏览器及淘宝天猫 PC 端的内置渲染引擎,无需额外添加浏览器前缀。
- 性能优化:超大宽高设置可能影响页面渲染性能,若无需适配特殊布局,可适当减小宽高值(如
width: 100vw、height: 100vh)。 - 背景资源:背景图 URL 为示例地址,实际使用时需替换为自身项目的资源链接,确保资源可正常访问。
- 交互配合:若需通过 JS 控制元素显示 / 隐藏,可结合
classList.add()/classList.remove()操作.popup-hidden类,避免直接修改样式属性。
通过以上优化后的 CSS 代码,可高效实现淘宝天猫 PC 端元素的隐藏需求,同时兼顾布局稳定性和场景兼容性,适用于店铺装修、活动页面开发等多种场景。
-
ComfyUI-GGUF-VLM 结合 llama.cpp GPU 加速:实现图像反推秒级效率
众所周知,ComfyUI中QwenVL节点通过Qwen3VL模型能够将视觉内容转化为详细的文字描述,它广泛应用于图像反推提示词、智能标注、视觉问答等场景。同时把它接入到最近出的Z-Image模型中反推生图是leepoet感觉最合适的搭配组合,毕竟都是阿里出品,在反推生图方面语义对齐这一块应该会更兼容。事实也是如此,在lee poet不断的测试下,拿来反推的图相似度个人觉得大部份生图与原图能达到70%以上。
但是Qwen3VL的缺点就是有些慢,对于4060Ti 16G而言,反推大概在1分钟以内。而3060 12G大概在2分钟左右。自从Z-Image前段时间出了之后,Leepoet就一直在用它接入到Z-Image洗图。就拿4060TI16G来讲,反推50秒出图20秒,这样的效率相较于一些专为速度优化的模型(如Florence2、Joy)存在一定差距,导致其在需要高频、批量处理的“洗图”等场景下略显尴尬,但这种效率上的差异本质上源于模型在设计目标上的根本不同,从而使得它们在应用场景上“各有千秋” 。


但基于Qwen3VL在反推理解能力准确性、丰富度较好的基础上,所以这段时间也就一直这样将就的用着。
一直到昨天从群友处了解另一个好使的节点ComfyUI-GGUF-VLM。才知道除了GGUF加速模型外还可以使用 llama.cpp对模型进行加速。

以下是ComfyUI-GGUF-VLM节点的简介:
ComfyUI 的多模态模型推理插件,专注于 Qwen 系列视觉语言模型,支持多种推理后端。 ## ✨ 核心功能 ### 主要侧重 **🎯 视觉语言模型 (VLM)** - **Qwen2.5-VL** / **Qwen3-VL** - 主要支持的视觉模型 - LLaVA、MiniCPM-V 等其他视觉模型 - 单图分析、多图对比、视频分析 **💬 文本生成模型** - Qwen3、LLaMA3、DeepSeek-R1、Mistral 等 - 支持思维模式 (Thinking Mode) ### 推理方式 - ✅ **GGUF 模式** - 使用 llama-cpp-python 进行量化模型推理 - ✅ **Transformers 模式** - 使用 HuggingFace Transformers 加载完整模型 - ✅ **远程 API 模式** - 通过 Ollama、Nexa SDK、OpenAI 兼容 API 调用 ### 主要特性 - ✅ **多推理后端** - GGUF、Transformers、远程 API 灵活切换 - ✅ **Qwen-VL 优化** - 针对 Qwen 视觉模型的参数优化 - ✅ **多图分析** - 最多同时分析 6 张图像 - ✅ **设备优化** - CUDA、MPS、CPU 自动检测 - ✅ **Ollama 集成** - 无缝对接 Ollama 服务 ## 🤖 支持的模型 ### 🎯 主要支持 (推荐) **视觉模型:** - **Qwen2.5-VL** (GGUF / Transformers) - **Qwen3-VL** (GGUF / Transformers) **文本模型:** - Qwen3、Qwen2.5 (GGUF / Ollama) - LLaMA-3.x (GGUF / Ollama) ### 🔧 其他支持 **视觉模型:** LLaVA、MiniCPM-V、Phi-3-Vision、InternVL 等 **文本模型:** Mistral、DeepSeek-R1、Phi-3、Gemma、Yi 等 > 💡 **推理方式:** > > - GGUF 格式 → llama-cpp-python 本地推理 > - Transformers → HuggingFace 模型加载 > - Ollama/Nexa → 远程 API 调用 ## 📦 安装 ```bash cd ComfyUI/custom_nodes git clone https://github.com/walke2019/ComfyUI-GGUF-VLM.git cd ComfyUI-GGUF-VLM pip install -r requirements.txt # 可选: 安装 Nexa SDK 支持 pip install nexaai ``` ## 🚀 快速开始 ### 本地 GGUF 模式 1. 将 GGUF 模型文件放到 `ComfyUI/models/LLM/GGUF/` 目录 2. 在 ComfyUI 中添加节点: - **Text Model Loader** - 加载模型 - **Text Generation** - 生成文本 ### 远程 API 模式 1. 启动 API 服务 (Nexa/Ollama): ```bash nexa serve # 或 ollama serve ``` 2. 在 ComfyUI 中添加节点: - **Remote API Config** - 配置 API 地址 - **Remote Text Generation** - 生成文本 ## 📋 可用节点 ### 文本生成节点 - **Text Model Loader** - 加载本地 GGUF 模型 - **Text Generation** - 文本生成 - **Remote API Config** - 远程 API 配置 - **Remote Text Generation** - 远程文本生成 ### 视觉分析节点 - **Vision Model Loader (GGUF)** - 加载 GGUF 视觉模型 - **Vision Model Loader (Transformers)** - 加载 Transformers 模型 - **Vision Analysis** - 单图分析 - **Multi-Image Analysis** - 多图对比分析 ### 🆕 工具节点 - **Memory Manager (GGUF)** - 显存/内存管理工具 - 清理已加载的模型 - 强制垃圾回收 - 清理GPU缓存 - 显示显存使用情况 ### 工具节点 - **System Prompt Config** - 系统提示词配置 - **Model Manager** - 模型管理器 ## 💭 思维模式 支持 DeepSeek-R1、Qwen3-Thinking 等模型的思维过程提取。 启用 `enable_thinking` 参数后,会自动提取并分离思维过程和最终答案。 ## 📁 项目结构 ``` ComfyUI-GGUF-VLM/ ├── config/ # 配置文件 ├── core/ # 核心推理引擎 │ └── inference/ # 多后端推理实现 ├── nodes/ # ComfyUI 节点定义 ├── utils/ # 工具函数 └── web/ # 前端扩展 ``` ##节点github地址:https://github.com/walke2019/ComfyUI-GGUF-VLM
安装好节点后,可以先通过启动安装一次该节点的依赖、库。然后再下载GGUF模型:
模型地址:https://huggingface.co/mradermacher/Qwen2.5-VL-7B-NSFW-Caption-V3-abliterated-GGUF/tree/main?not-for-all-audiences=true

放到对应的模型文件夹:

.\ComfyUI\models\text_encoders\qwenclip

.\ComfyUI\models\LLM\GGUF

这里建议配置好的可以用以下这两个模型,因为官方的推是

以上基本上就已经安装好节点,并把模型下载好并可进入使用了。但是在这种情况下只能通过CPU进行推理(在速度方面跟QWEN3VL其实并没有太大的区别,有区别的就是这些模型是破限的)。并没有使用llama-cpp-python。

可以这么说,同样为3060 12G的显卡,ComfyUI-QwenVL节点反推一张图的时间在2分左右,而ComfyUI-GGUF-VLM通过llama-cpp-python调用GPU加速可以让反推时间缩短到几秒钟。
那么什么是llama-cpp-python?
llama-cpp-python 是 llama.cpp 的 Python 绑定库,提供高性能的本地大语言模型推理能力,支持 CPU、CUDA GPU、Metal 等多种硬件加速,是部署本地 LLM 应用的常用工具。支持 CPU、CUDA(NVIDIA GPU)、Metal(Apple Silicon)、OpenCL 等多种后端的高性能推理。
话虽如此,正常使用ComfyUI-GGUF-VLM这个节点,在没有安装llama-cpp-python这个库的情况反推是不支持GPU的,但是要想让反推达到秒级的速度,就要先准备一些环境。
步骤前瞻:
先安装好节点并下载模型->安装Visual Studio->配置MSVC系统变量->安装配置对应版本的CUDA->通过CUDA调用MSVC构建llama-cpp-python
1.安装Visual Studio,并配置好MSVC系统变量。
lee poet之前写过一个怎么配置环境篇:加载ComfyUI出现WARNING: Failed to find MSVC解决方案,配置好记得重启。。

2.验证cl,rc,link。如果有返回路径说明已经配置好。

3.安装CUDA及cudnn,并配置CUDA环境变量。
因为lee poet所使用的comfyui环境是的pytorch version: 2.5.1+cu124

所以要下载对应的cuda版本,我下载的是CUDA Toolkit 12.4的CUDA Toolkit 12.4 Downloads Installer for Windows 10 x86_64

同时再下载cudnn,下载地址:https://developer.nvidia.com/rdp/cudnn-archive,找到对应的CUDA版本号
Download cuDNN v8.9.7 (December 5th, 2023), for CUDA 12.x


下载好用,先进行cuda的安装,*如果之前您有安装其它低版本的CUDA,在不使用的情况下可以先通过卸载程序的控制面板里先卸载。再进行安装:


OK




以上安装都说有报错,重启电脑再继续安装即可。安装完后,我们先配置环境变量。

添加CUDA的环境变量(如果已经存在,则不需要重复添加)

配置好后,解压cudnn-windows-x86_64-8.9.7.29_cuda12-archive.zip,可以看到三个文件夹

把红框圈住的地方COPY到刚刚安装好的CUDA的C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.4这个文件夹内

继续给cuDNN添加相应的环境变量

#leepoet的CUDA及cuDNN的环境变量如下: C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.4\bin C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.4\include C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.4\lib C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.4\libnvvp配置好环境变量后,验证:nvcc -V


粘贴到C:\Program Files\Microsoft Visual Studio\2022\Community\MSBuild\Microsoft\VC\v170\BuildCustomizations这个目录下

以上就算是把llama-cpp-python安装的环境配置好了。下面再通过虚拟环境构建安装llama-cpp-python。
打开启动器命令提示符,可以通过这个直接到这个整合包的虚拟环境。

可以看到红框框住的这个标识,实际上就是这个整合包的虚拟环境的标识

set CMAKE_ARGS=-DGGML_CUDA=on python.exe -m pip install llama-cpp-python --force-reinstall --no-cache-dir命令/参数 解释 set CMAKE_ARGS="-DGGML_CUDA=on"设置一个名为 CMAKE_ARGS的环境变量,其值为-DGGML_CUDA=on。这个变量会传递给后续的编译过程,指示构建系统启用对CUDA的支持。python.exe -m pip install使用Python模块方式运行pip进行安装,这通常比直接运行 pip命令更可靠。llama-cpp-python要安装的Python包名称,它是对C++库 llama.cpp的Python封装。--force-reinstall强制重新安装该包及其所有依赖。如果已存在安装版本,会先卸载再安装,确保是最新编译的版本。 --no-cache-dir禁用pip的缓存。这能确保pip不会使用之前下载或编译的缓存文件,而是从头开始获取源码并进行编译。 这条命令组合起来的效果是:强制pip忽略缓存,重新从源码编译并安装支持CUDA的
llama-cpp-python库。通过pip install llama-cpp-python安装的是仅支持CPU的版本。通过从源码编译并设置CMAKE_ARGS,可以解锁GPU加速功能,在处理大语言模型时能获得数倍的速度提升。执行命令后


先是下载库从源码编译,可能需要十几到二十分钟。

可以看到已经安装成功了。*安装后完有其它库的冲突能解决就自己解决,LeePoet是选择性忽略,主打一个能用就行。
后面就是关掉启动器,重新启动。它会自己解析并检验各种依赖。

启动完进入UI后,这次从反推到Z-image生图768x1536px的图片大概在40秒左右了。

李诗人这次使用的是家用电脑配置相对一般,但是能有这个速度还是相对满意的。
-
NAS玩家必备:Lucky实现域名解析、自动证书与安全反代全攻略
Lucky是@古大羊开发的一款家庭公网利器,专为NAS、软路由等内网设备打造的全能网络工具,集成动态域名解析(DDNS)、反向代理、SSL证书自动续签、端口转发、内网穿透等核心功能,支持IPv4/IPv6双栈访问,是2025年NAS玩家必备的免费实用神器。

对于国内的家庭网络环境,Lucky尤其适合搭建在 NAS(如威联通 QNAP)、软路由或轻量级 Linux 服务器上,用于实现外网访问(内网穿透和反向代理)家庭设备或服务,简单易用稳定也基本不需要怎么折腾。
前言
多家DNS服务商(阿里云、腾讯云、Cloudflare等),可自动将动态公网IP与固定域名绑定,实现域名访问NAS。配置时需获取域名服务商的API密钥(AccessKey ID和Secret),填写主域名和泛域名(如example.com和*.example.com),Lucky会自动同步解析记录,
通过ACME协议自动申请Let’s Encrypt免费SSL证书,支持泛域名证书,证书到期前约36天自动续签,无需手动操作。配置时选择ACME方式,填写域名列表和DNS服务商Token,开启DNS查询强制IPv4和仅使用TCP通道即可。
支持HTTP/HTTPS反向代理,可将不同服务统一到单一入口端口,通过二级域名区分访问(如movie.example.com → Jellyfin服务)。监听端口可自定义(如443、8443等),需在路由器中设置端口转发。支持TLS加密,可隐藏真实端口,提升安全性。
配置流程
- 设置DDNS:添加DDNS任务,选择服务商并填写API密钥,配置域名解析
- 申请SSL证书:选择ACME方式,关联DNS服务商,申请泛域名证书
- 配置反向代理:添加Web服务规则,设置监听端口和TLS,添加子规则指定前端域名和后端服务地址
- 端口转发:在路由器中将监听端口转发到NAS内网IP
部署平台:威联通NAS TS-673A
Lucky版本:2.17.3 linux(x86_64)
部署方式:Docker Compose
网络状况:默认已经折腾好公网IP
另外还需要我们提前准备Token,这个可从域名托管商处获得,我们以DNSPod为例。

将ID和Token复制下来备用。

部署方式
打开威联通的Container Station,创建新的应用程序。部署代码如下:
services:
lucky:
image: gdy666/lucky
container_name: lucky
restart: always
volumes:
-'/share/Container/lucky:/goodluck'# 这步必须做,否则重启配置会消失,可直接照抄配置。
network_mode: host
# host模式, 同时支持IPv4/IPv6, Liunx系统推荐
# 桥接模式, 只支持IPv4,windows 不推荐使用docker版本
# 我仍然不建议使用默认的桥接模式,如作者所说很容易出问题,已经试验过
修改基础配置
内网环境下,输入NAS_IP:16601即可访问管理界面。默认的账户密码为 666/666

但如果像我一样,远程折腾,可以利用威联通自带的Browser Station。也可将16601端口通过路由器转发到公网,通过外网访问(公网IP:16601)进行配置。
从版本2.13.9开始,在默认配置中,外网访问开关处于关闭状态。然而,在 lucky_base.lkcf 配置初始化后的十分钟内,系统允许外网访问。如果在这十分钟内执行了配置保存操作,则外网访问开关的设置将优先生效。如果错过了这个时间,您需要通过删除 lucky_base.lkcf 配置文件并重启 Lucky 进程的方式,使 lucky_base.lkcf 配置再次初始化。

登入后如下图所示进行设置,除了登陆验证修改默认账号密码外,其他凭大家需求。

安全入口部分为了安全考虑能改则改,比如若修改为/ydxian,则内外网无论那个想要访问Lucky的登陆面板,最后都要在完整的访问地址后加上/ydxian。如果不加,会得到如下结果。

动态域名(DDNS)
这里需要使用到上文域名托管商所获的Token。
左侧栏第三项「动态域名」,点击「添加任务」。

选择托管商,我这里选择的是DnspodCN(如果你的DNS服务商不在列表当中,则使用万能的自定义Callback模式),粘贴ID与Token。根据你的网络情况选择启用同步类型(IPv4或IPv6),我的为IPv4公网。

接着下拉界面,点击「添加同步记录」。

记录栏中先填写主域名(二级域名),回车换到下一行,再填写通配符域名(所有三级子域名),如果你有更多需求则回车另起一行再继续添加即可。
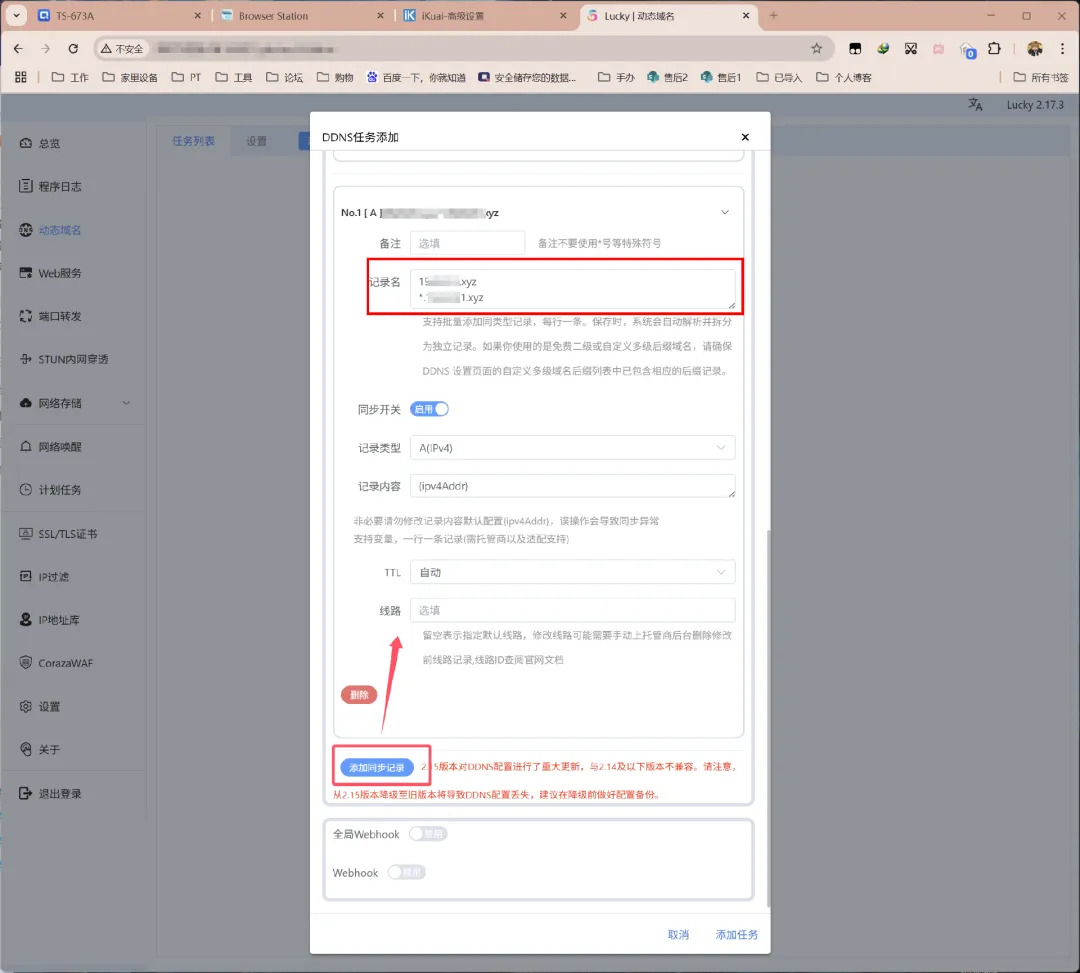
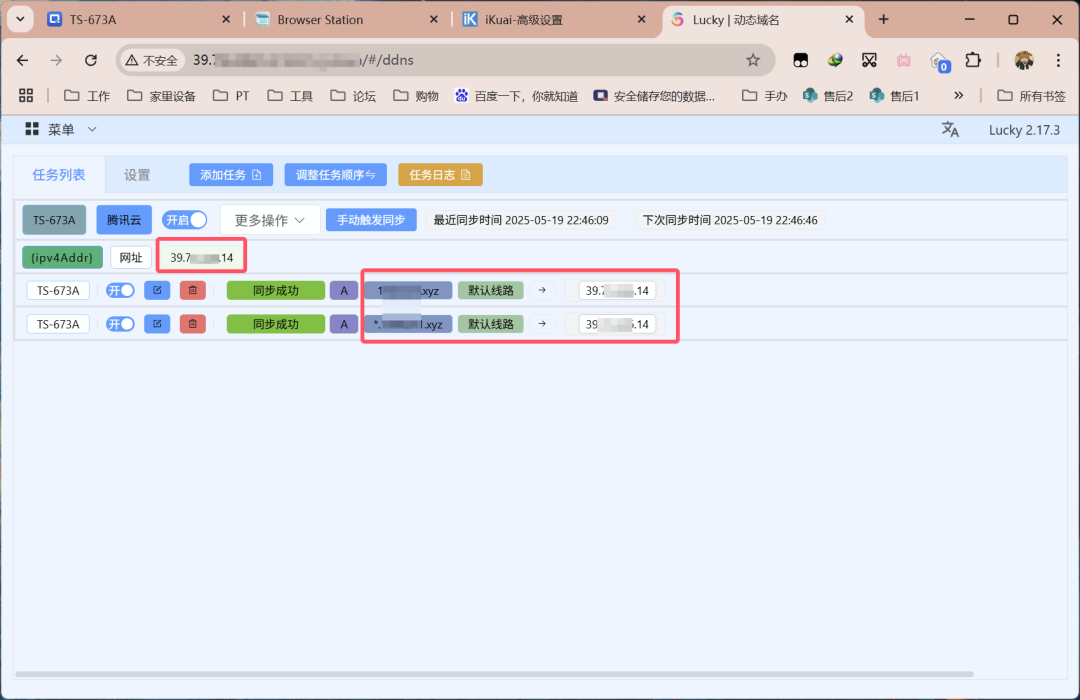
点击「添加任务」,Lucky就会自动保存并自动进行同步。成功后的界面如下。
SSL/TLS证书
这里依然需要使用到上文域名托管商所获的Token。
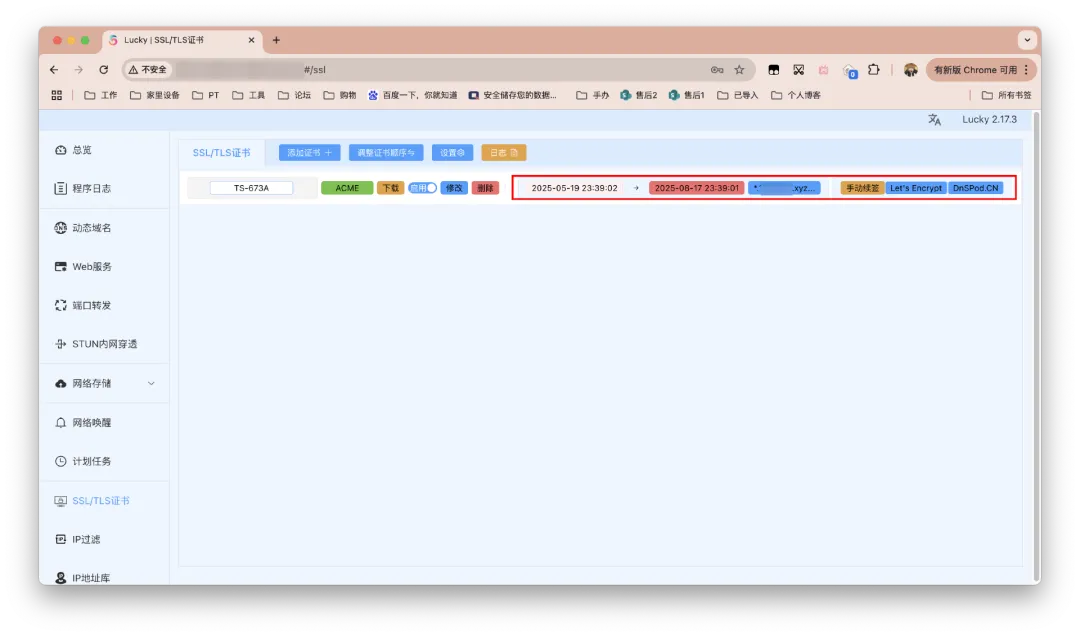
左侧栏点击「SSL/TLS证书」,接着点击「添加证书」。
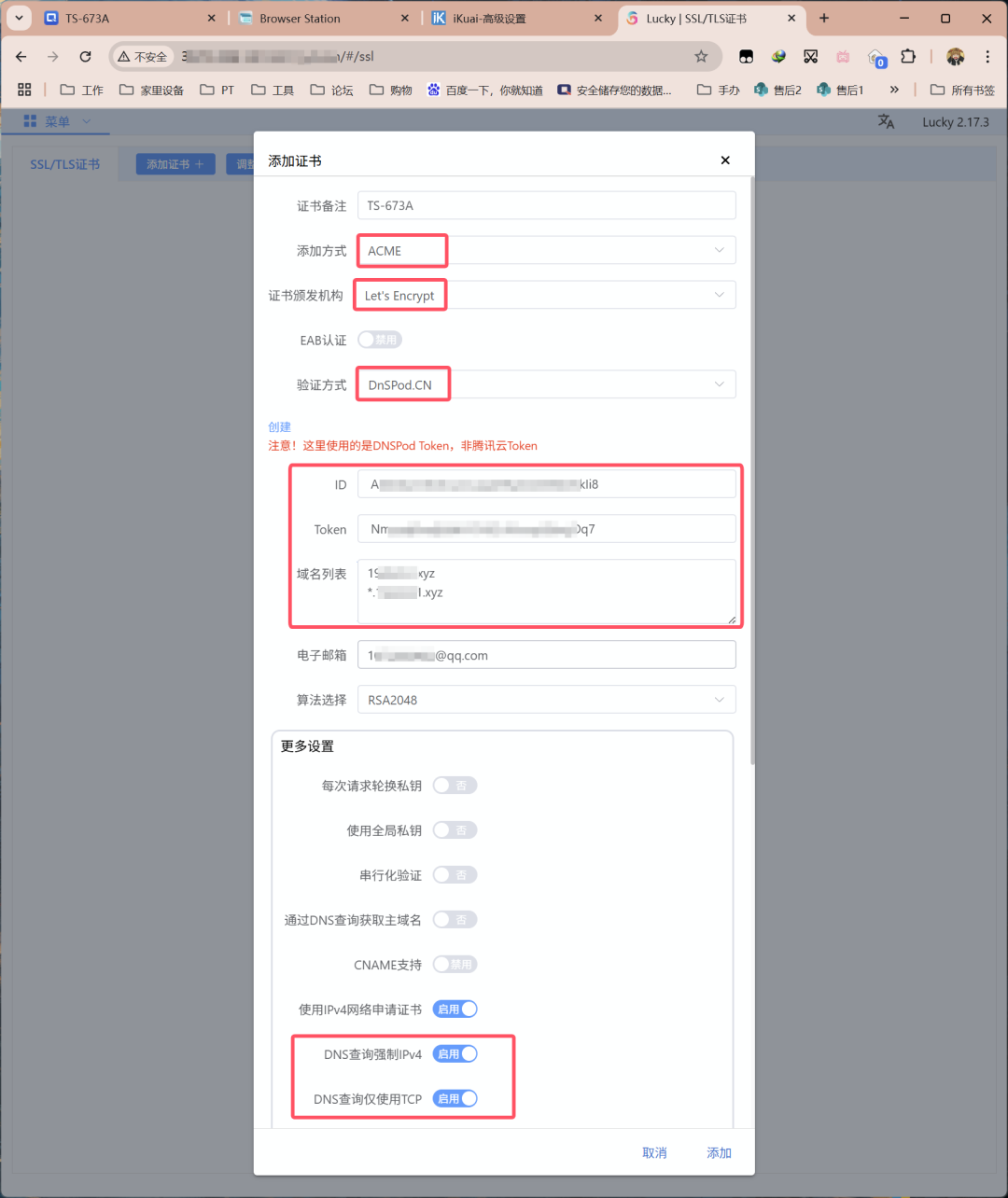
对证书进行备注,添加方式选择ACEM,ACME类型证书会在到期前约36天自动续签。证书颁发机构选择Let’s Encrypt。验证方式要与上文动态域名解析的保持一致。粘贴ID和Token,补充域名列表,这里同样与上文一致。更多设置勾选DNS查询强制IPv4和DNS查询仅使用TCP。搞定后直接点击「添加」。
如果你有其他证书需求,也可自行上传或指定证书路径。
稍等一会儿,成功的结果界面如下。
Web服务
这里开始配置反向代理相关。
左侧栏点击「Web服务」,点击「添加Web服务规则」。
对服务规则进行命名。监听类型同样根据实际网络情况选择。监听端口自定(我预设为7086,但IPv6可忽略这项),要是未被占用的可用端口,后面还要对这个端口进行转发,可惜国内IPv4的443基本不能用。我们已然申请证书要通过HTTPS访问,TLS需要开启。
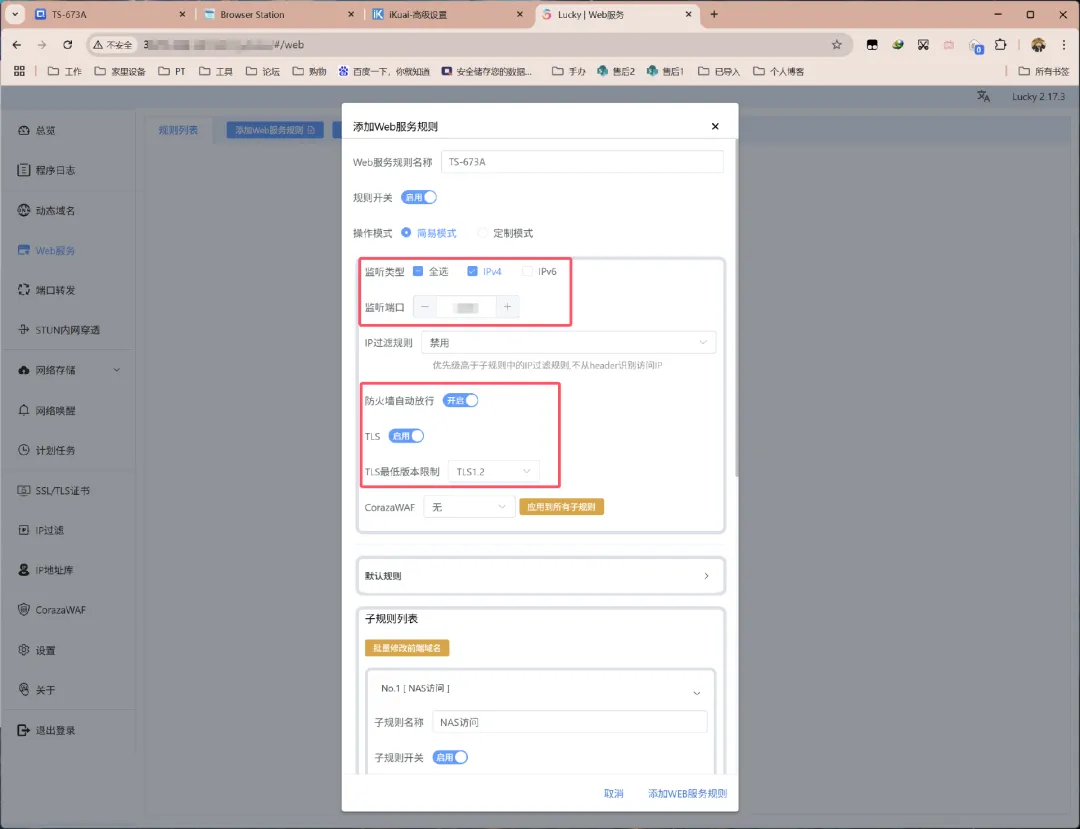
接着是默认规则,选择关闭链接,会对下面的子规则生效。就是如果访问的地址与子规则的配置不符,不会返回任何响应(如 403、404、503 等),而是直接丢弃请求。这里其实完全没必要管,官方文档也有提示。
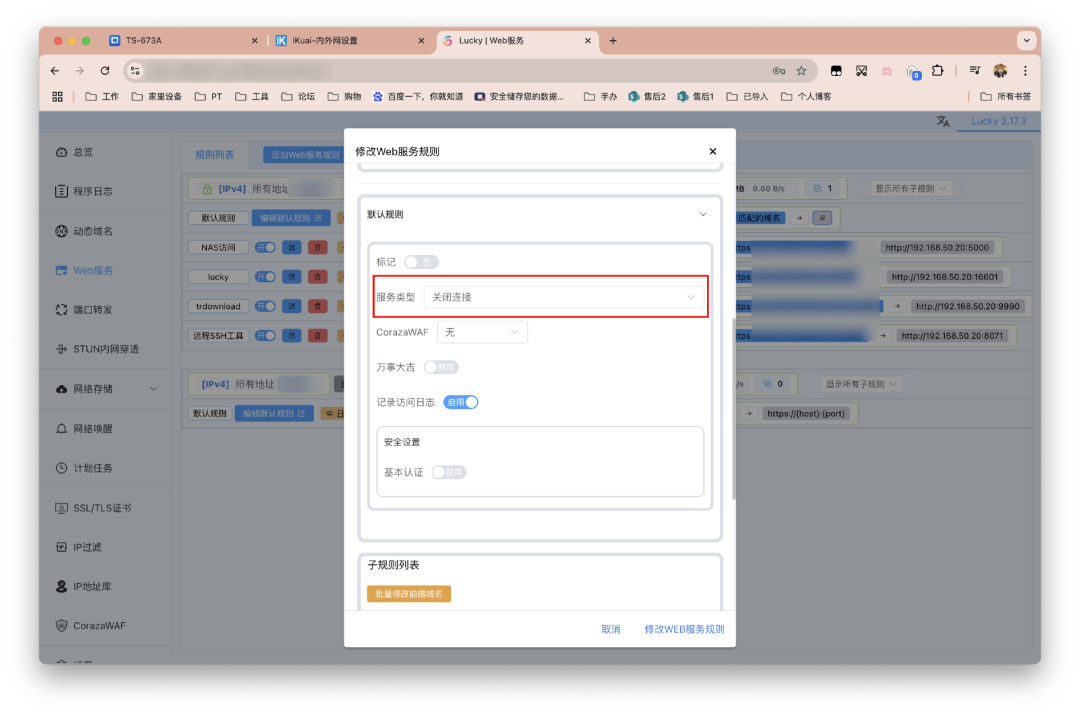
最后添加子规则。现在的Lucky支持批量修改前端域名,如果我们实行域名年抛策略会非常方便。
以上一篇部署的TR下载器为例,服务类型选择反向代理。前端地址填写纯粹的域名,不要带杂七杂八内容,域名前缀自定义即可。后端地址则要填写内网完整的访问地址,如下图所示。
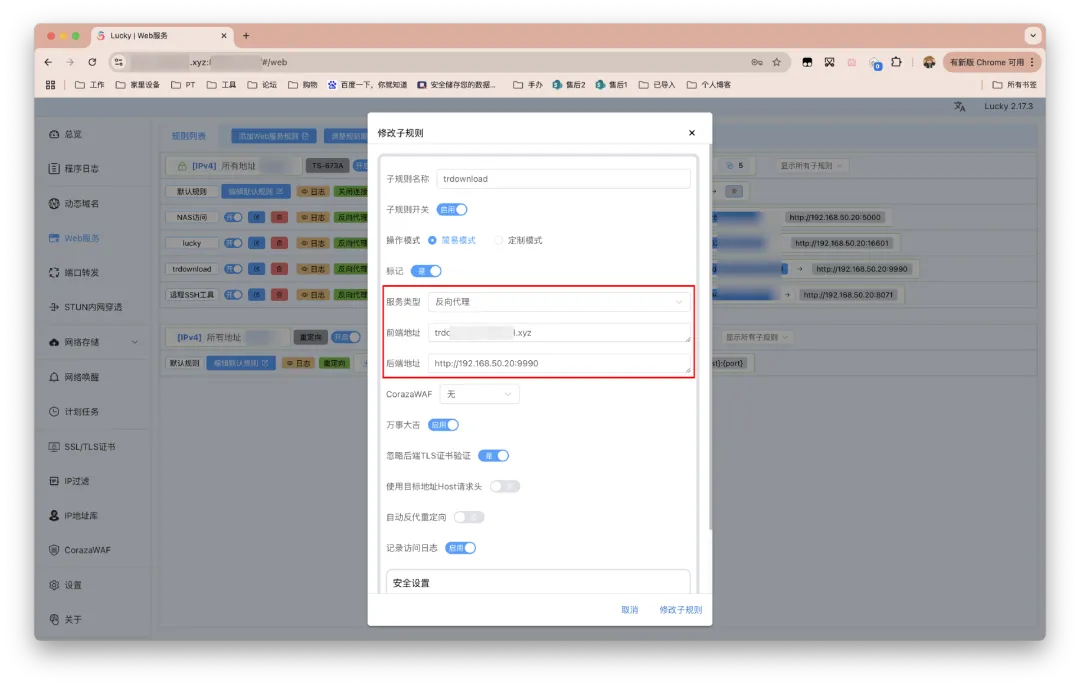
确认无误后,右下角点击「添加/修改子规则」即可。如下图的红色框标注部分便是以后外网访问TR的地址。

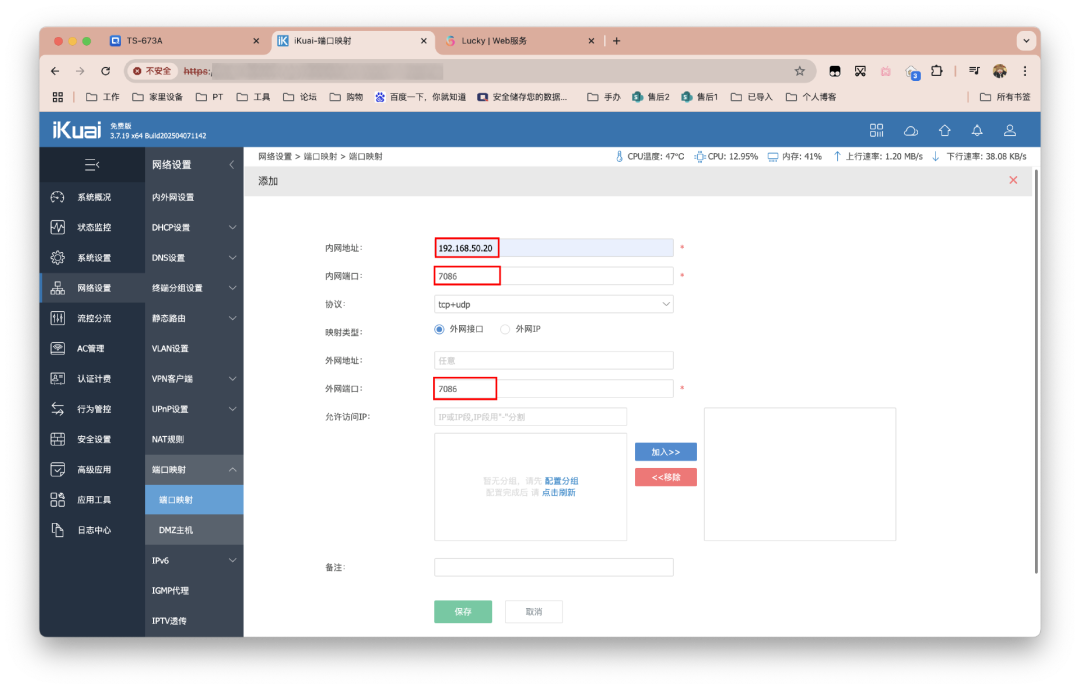
最后还差一步,就是IPv4用户需要对监听端口进行转发。
来到路由器,设置端口转发/映射,内网地址填写为NAS内网IP,端口则为上文设置的监听端口,最后保存即可。
至此已经实现家庭NAS外网访问方案。后续也可以将Lucky本身以及其他服务都加入进去。
情况补充
当时写Lucky流程试验后碰到的问题:
在手机浏览器输入域名+监听端口时,会连接失败,必须要手动再补上https://。
因此我们要添加 HTTP → HTTPS 的自动跳转规则。
继续点击「添加Web服务规则」。
配置如下。
监听端口和前面的保持一致。TLS不要开。
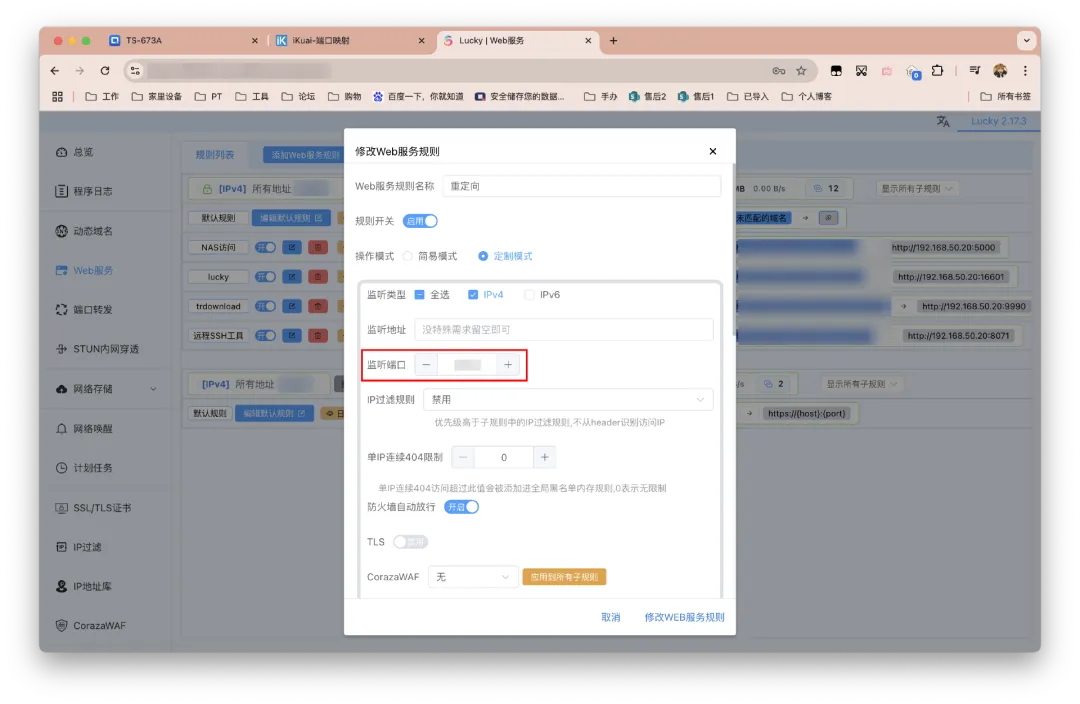
接着下拉界面编辑默认规则。
服务类型选择重定向。
默认目标地址填写https://{host}:{port}。
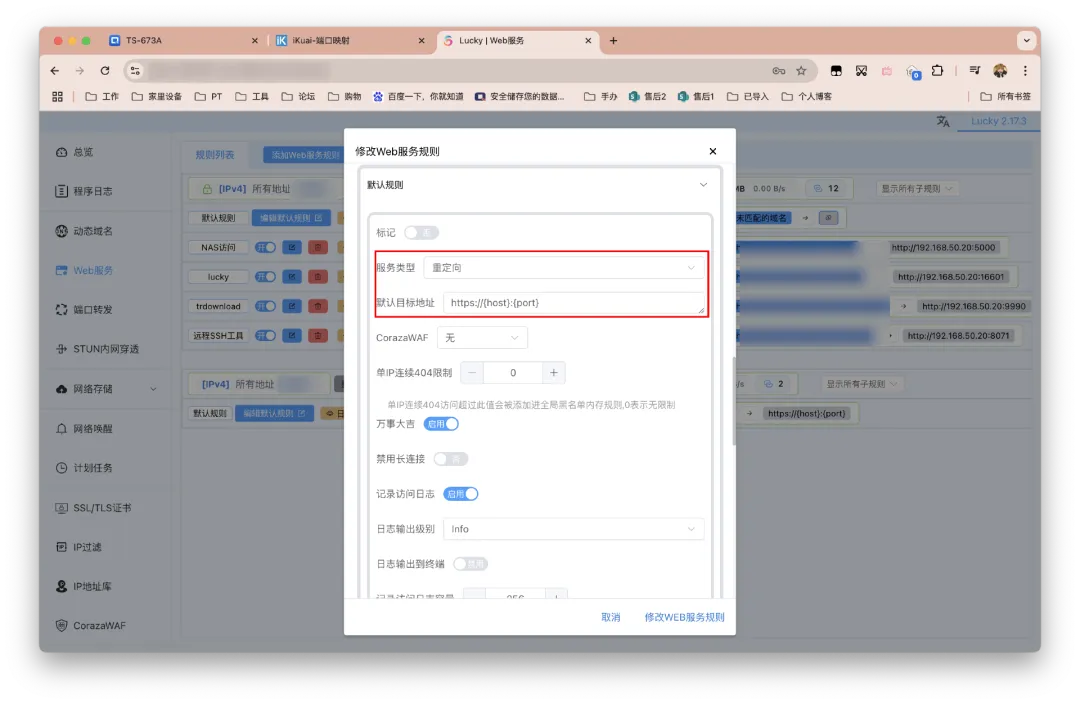
修改/保存即可。
Lucky特别适合家庭NAS环境,可将Jellyfin、Emby、qBittorrent等各类服务通过二级域名统一访问,实现”一个域名+N个服务”的便捷管理。相比传统方案(DDNS-GO + Nginx Proxy Manager),Lucky将多个工具功能整合到一个界面,操作更简单,配置更直观,适合新手玩家快速上手。
安全建议:首次使用后务必修改默认密码,设置安全入口路径,关闭外网访问开关,定期备份配置文件。对于公网IPv4用户,建议在路由器中设置端口转发;IPv6用户需确保光猫和路由器开启IPv6桥接模式。
-
WEBP/PNG/HEIC批量转JPG:李哥的一键式图片格式转换神器

兄弟们,是不是经常遇到这些头疼事?
- 从网站扒下来的图片全是 WEBP 格式,编辑软件打不开?
- PNG 图片虽然清晰,但体积太大,上传发布总受限制?
- 用苹果设备拍的照片是 HEIC 格式,在Windows电脑上就成了“天书”?
别慌!李哥出手,必属精品!今天给大家带来的这款 「批量图片格式转换JPG工具」,就是专门治这些“格式不服”的!它就像你图片库里的“格式统一大师”,管你什么WEBP、PNG还是HEIC,统统给咱变成最通用、最省心的 JPG 格式!
真正的“傻瓜式”操作:把脚本和图片放一个文件夹,双击运行,剩下的交给程序。自动安装环境、自动转换、自动整理文件,你只管喝杯茶等着收JPG就行!特别加入了 HEIC 格式支持,再也不用为苹果照片在电脑上打不开而发愁了。转换后的JPG、原始文件、转换失败的图片,会自动分门别类存到
convert/,source/,failed/三个文件夹里,井井有条,绝不乱套。万一有同名文件?不存在的!程序会自动给你加上序号,保证一个文件都不会被覆盖。下载脚本 -> 双击运行 -> 收获一文件夹整齐的JPG图片!
李哥已经把代码和详细的使用说明都准备好了,就等你来取。赶紧下载试试,从此告别图片格式转换的烦恼!做人呢,最重要的就是开心!用李哥的工具,让你的图片处理也开心起来!
核心解读:
作用:自动检查并安装必要的Python库(Pillow和pillow-heif)启用HEIC文件格式支持(苹果设备照片格式)
创建虚拟环境并安装python库
# 退出当前环境 deactivate # 删除损坏的虚拟环境 cd ~/Documents/env rm -rf myenv # 重新创建虚拟环境 python3 -m venv myenv # 激活新环境 source myenv/bin/activate # 检查pip是否正常 pip --version # 安装Pillow pip install Pillow # 检查安装是否成功 python3 -c "from PIL import Image; print('Pillow安装成功!')"创建三个目录:
convert/– 存放转换后的JPG文件source/– 存放原始图片文件failed/– 存放转换失败的文件
智能移动文件到指定目录,自动处理重名文件(添加序号)输出格式JPG (.jpg) – 通用的有损压缩图片格式
文件整理逻辑
转换前目录结构: 当前目录/ ├── image1.webp ├── image2.png ├── image3.heic └── convert_images.py 转换后目录结构: 当前目录/ ├── convert/ # 转换后的JPG文件 │ ├── image1.jpg │ ├── image2.jpg │ └── image3.jpg ├── source/ # 原始文件(已移动) │ ├── image1.webp │ ├── image2.png │ └── image3.heic ├── failed/ # 转换失败的文件 └── convert_images.py实现代码:
#!/usr/bin/env python3 # -*- coding: utf-8 -*- import os import glob import shutil import sys import subprocess def check_and_install_dependencies(): """检查并安装必要的依赖""" dependencies = ['Pillow', 'pillow-heif'] missing_deps = [] # 检查Pillow try: from PIL import Image print("✓ Pillow 已安装") except ImportError: missing_deps.append('Pillow') # 检查pillow-heif try: import pillow_heif print("✓ pillow-heif 已安装") except ImportError: missing_deps.append('pillow-heif') # 安装缺失的依赖 if missing_deps: print(f"❌ 缺少依赖: {', '.join(missing_deps)}") print("正在安装依赖...") for dep in missing_deps: try: if dep == 'Pillow': subprocess.check_call([sys.executable, '-m', 'pip', 'install', 'Pillow']) elif dep == 'pillow-heif': subprocess.check_call([sys.executable, '-m', 'pip', 'install', 'pillow-heif']) print(f"✓ {dep} 安装成功") except subprocess.CalledProcessError: print(f"❌ {dep} 安装失败,尝试使用镜像源...") try: subprocess.check_call([sys.executable, '-m', 'pip', 'install', dep, '-i', 'https://pypi.tuna.tsinghua.edu.cn/simple/']) print(f"✓ {dep} 安装成功(使用镜像源)") except: print(f"❌ {dep} 安装失败,请手动安装: pip install {dep}") return False # 重新检查 try: from PIL import Image import pillow_heif print("✓ 所有依赖安装成功") return True except ImportError as e: print(f"❌ 依赖安装后仍然失败: {e}") return False return True def setup_heic_support(): """设置HEIC支持""" try: import pillow_heif pillow_heif.register_heif_opener() print("✓ HEIC格式支持已启用") return True except Exception as e: print(f"❌ HEIC支持初始化失败: {e}") return False def create_directories(): """创建必要的目录""" directories = ['convert', 'source', 'failed'] for directory in directories: if not os.path.exists(directory): os.makedirs(directory) print(f"✓ 创建目录: {directory}/") def move_file_to_directory(original_file, directory): """移动文件到指定目录""" try: filename = os.path.basename(original_file) destination = os.path.join(directory, filename) # 如果目标文件已存在,添加序号 counter = 1 base_name, ext = os.path.splitext(filename) while os.path.exists(destination): new_filename = f"{base_name}_{counter}{ext}" destination = os.path.join(directory, new_filename) counter += 1 shutil.move(original_file, destination) return True except Exception as e: print(f"⚠ 移动文件失败 {original_file}: {e}") return False def convert_image_file(input_file, temp_jpg_file, is_heic=False): """转换图片文件""" try: from PIL import Image if is_heic: # HEIC文件特殊处理 try: import pillow_heif heif_file = pillow_heif.open_heif(input_file) image = Image.frombytes( heif_file.mode, heif_file.size, heif_file.data, "raw", heif_file.mode, heif_file.stride, ) except: # 如果直接读取失败,尝试通过PIL打开 pillow_heif.register_heif_opener() image = Image.open(input_file) else: # 其他格式文件 image = Image.open(input_file) # 处理图片模式 if image.mode in ('RGBA', 'LA', 'P'): background = Image.new('RGB', image.size, (255, 255, 255)) if image.mode == 'P': image = image.convert('RGBA') if image.mode == 'RGBA': background.paste(image, mask=image.split()[-1]) else: background.paste(image) image = background elif image.mode != 'RGB': image = image.convert('RGB') # 保存为JPG image.save(temp_jpg_file, "JPEG", quality=85, optimize=True) return True, "成功" except Exception as e: return False, str(e) def batch_convert_images(): """批量转换图片""" print("=== 图片格式批量转换工具 ===") # 检查并安装依赖 if not check_and_install_dependencies(): print("❌ 依赖安装失败,无法继续") return # 设置HEIC支持 heic_supported = setup_heic_support() # 创建目录 create_directories() # 收集文件 files_to_convert = [] for pattern in ['*.webp', '*.WEBP', '*.png', '*.PNG', '*.heic', '*.HEIC']: files_to_convert.extend(glob.glob(pattern)) files_to_convert = sorted(list(set(files_to_convert))) files_to_convert = [f for f in files_to_convert if not any(f.startswith(d) for d in ['convert/', 'source/', 'failed/'])] if not files_to_convert: print("❌ 未找到可转换的图片文件") return # 分类统计 webp_files = [f for f in files_to_convert if f.lower().endswith('.webp')] png_files = [f for f in files_to_convert if f.lower().endswith('.png')] heic_files = [f for f in files_to_convert if f.lower().endswith('.heic')] print(f"找到 {len(files_to_convert)} 个文件:") print(f" WEBP: {len(webp_files)} 个, PNG: {len(png_files)} 个, HEIC: {len(heic_files)} 个") if heic_files and not heic_supported: print("⚠ HEIC文件将无法转换") # 转换统计 results = {'success': 0, 'failed': 0, 'skipped': 0} for i, input_file in enumerate(files_to_convert, 1): filename_without_ext = os.path.splitext(os.path.basename(input_file))[0] temp_jpg_file = filename_without_ext + ".jpg" final_jpg_path = os.path.join('convert', temp_jpg_file) # 跳过已存在 if os.path.exists(final_jpg_path): print(f"{i}/{len(files_to_convert)} ⚡ 跳过已存在: {final_jpg_path}") results['skipped'] += 1 continue file_size = os.path.getsize(input_file) / 1024 file_ext = os.path.splitext(input_file)[1].upper() is_heic = input_file.lower().endswith('.heic') print(f"{i}/{len(files_to_convert)} 🔄 转换: {os.path.basename(input_file)} ({file_size:.1f} KB)", end="") try: if is_heic and not heic_supported: success, message = False, "HEIC支持未启用" else: success, message = convert_image_file(input_file, temp_jpg_file, is_heic) if success: # 移动成功文件 if os.path.exists(temp_jpg_file): move_file_to_directory(temp_jpg_file, 'convert') move_file_to_directory(input_file, 'source') results['success'] += 1 print(" -> ✅ 完成") else: # 移动失败文件 move_file_to_directory(input_file, 'failed') results['failed'] += 1 print(f" -> ❌ 失败: {message}") except Exception as e: move_file_to_directory(input_file, 'failed') results['failed'] += 1 print(f" -> 💥 异常: {str(e)}") # 输出结果 print(f"\n=== 转换完成 ===") print(f"✅ 成功: {results['success']}, ❌ 失败: {results['failed']}, ⚡ 跳过: {results['skipped']}") if __name__ == "__main__": batch_convert_images() input("\n按Enter键退出...")