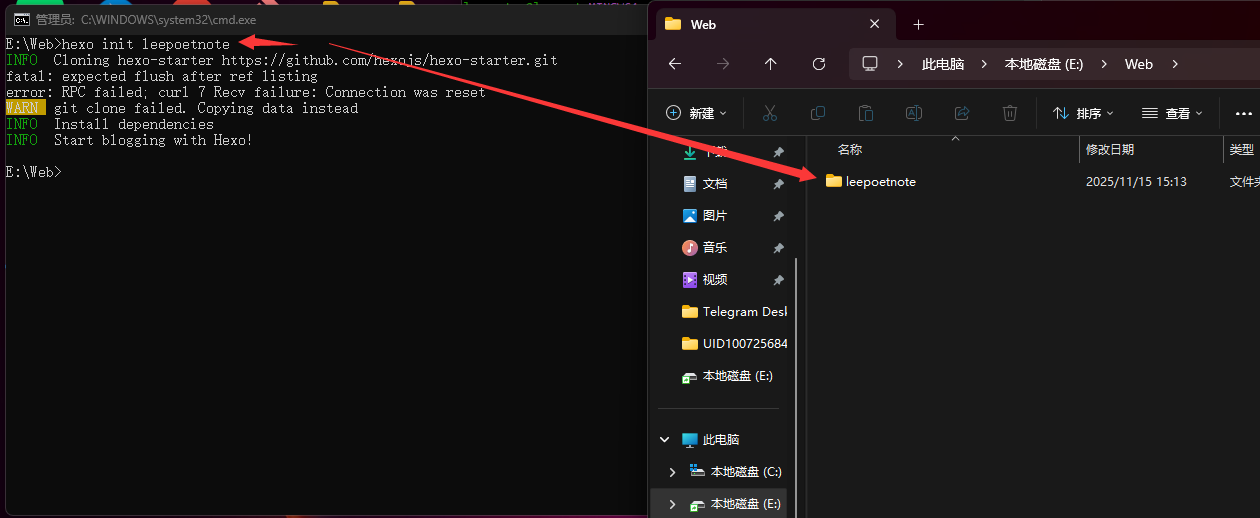
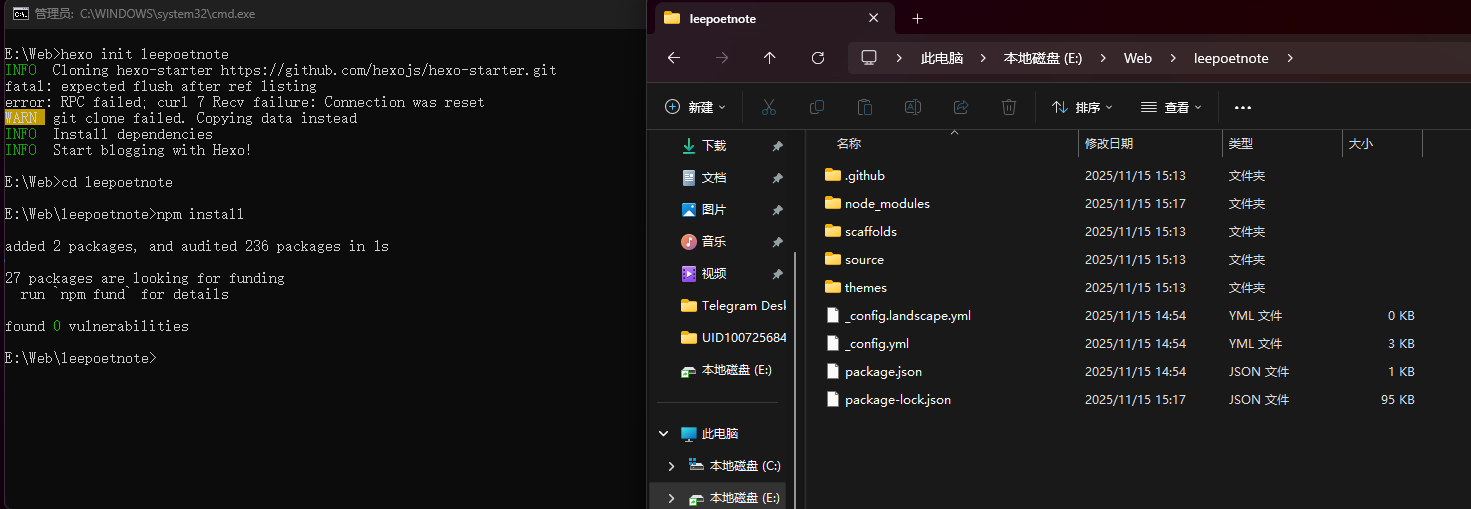
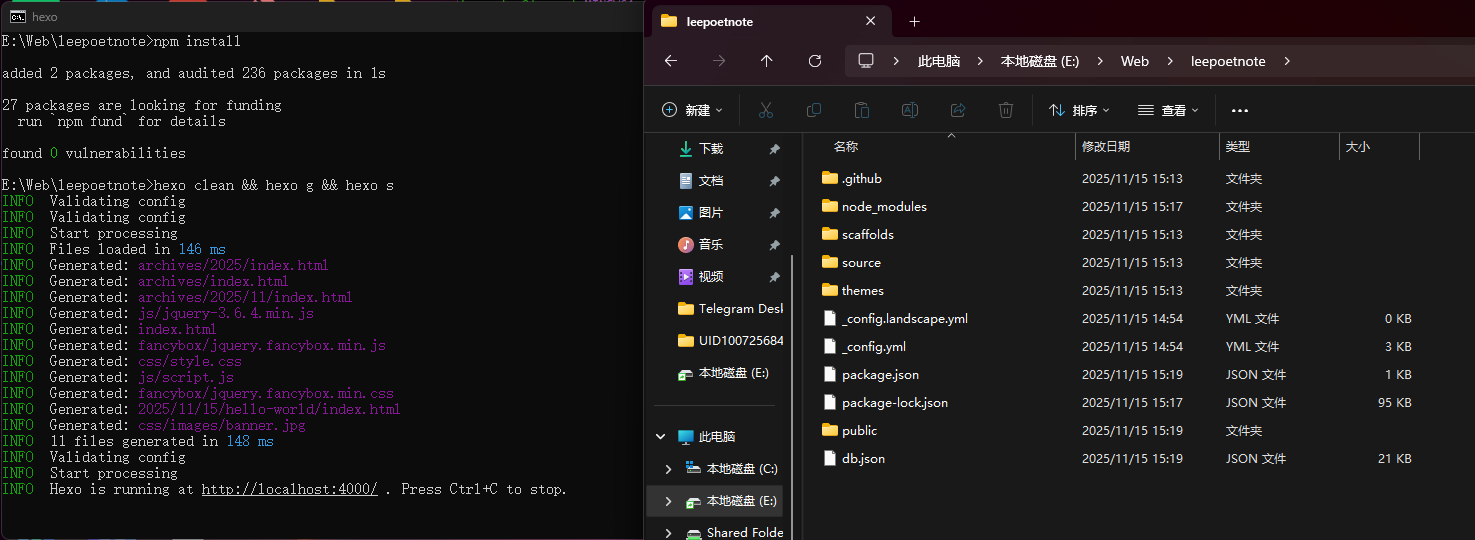
任何存在,都渴望一种不依附于他者的“自在”状态。一个博客也是如此。直接安装Node.js,如同让博客的灵魂与服务器的肉身紧密捆绑,是为“不自在”。
本文LeePoet将演示如何用Docker为Hexo博客构建一个“自洽的孤岛”。我们不仅讨论“拉取镜像”、“挂载目录”这些“术”,更探讨其背后的“道”——如何通过隔离实现和谐,通过约束获得自由。最终,博客将如LeePoet所追求的精神一般,独立、洁净,且便于迁徙,在任何新的“宿主”上都能瞬间重生。不欲让Node.js的烟火气沾染我清净的宿主机。于是,LeePoet决定效仿古人,为Hexo博客,造一座独立的园林。这篇随笔,记录了LeePoet如何用Docker这“芥子纳须弥”之术:先于宝塔面板迎回Docker这位“造园师”,再请来Node.js作为园中“嘉宾”。不仅要在容器这片“净土”内为Hexo“筑巢”,更妙的是,通过一扇名为“目录挂载”的月亮门,使园中之景(博客源码)与园外世界(宿主机)虚实相生,永不丢失。
先给宝塔面板安装DOCKER模块
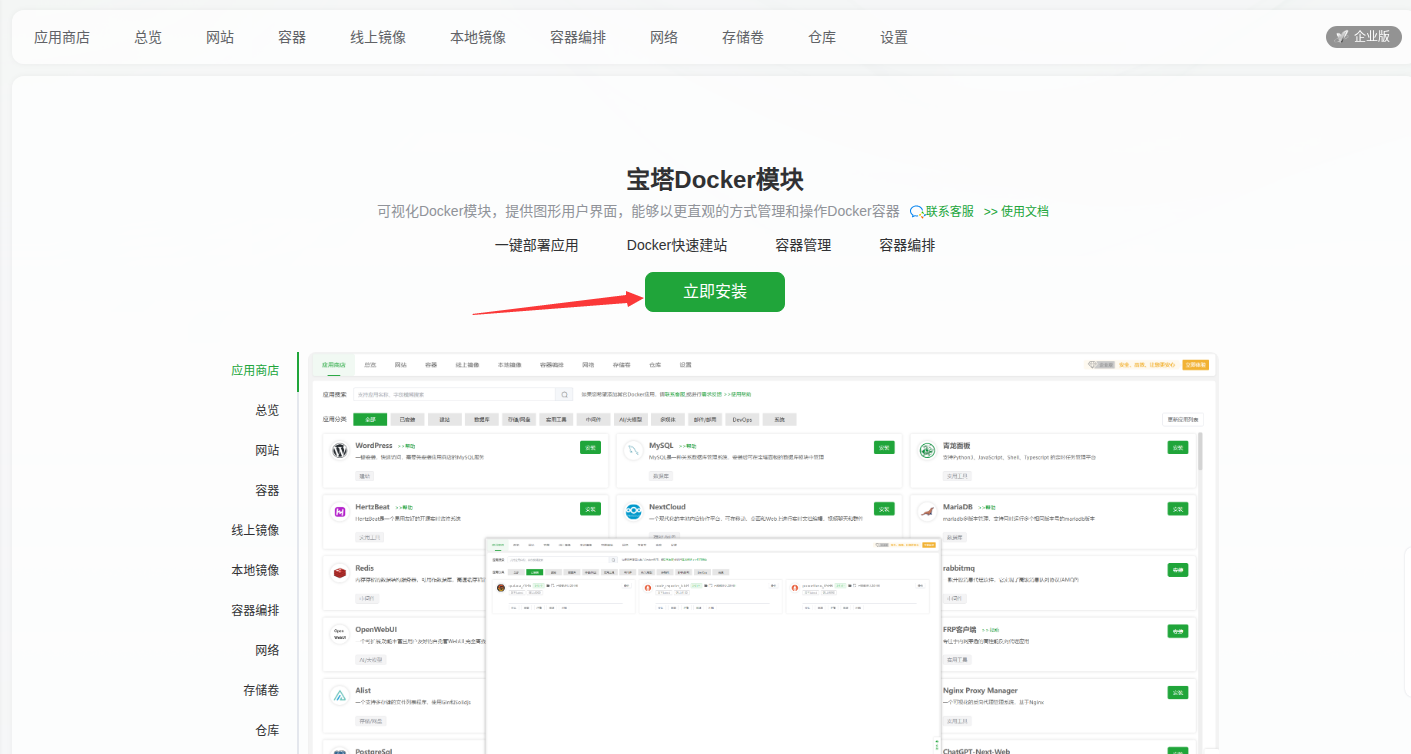
安装完毕刷新面板
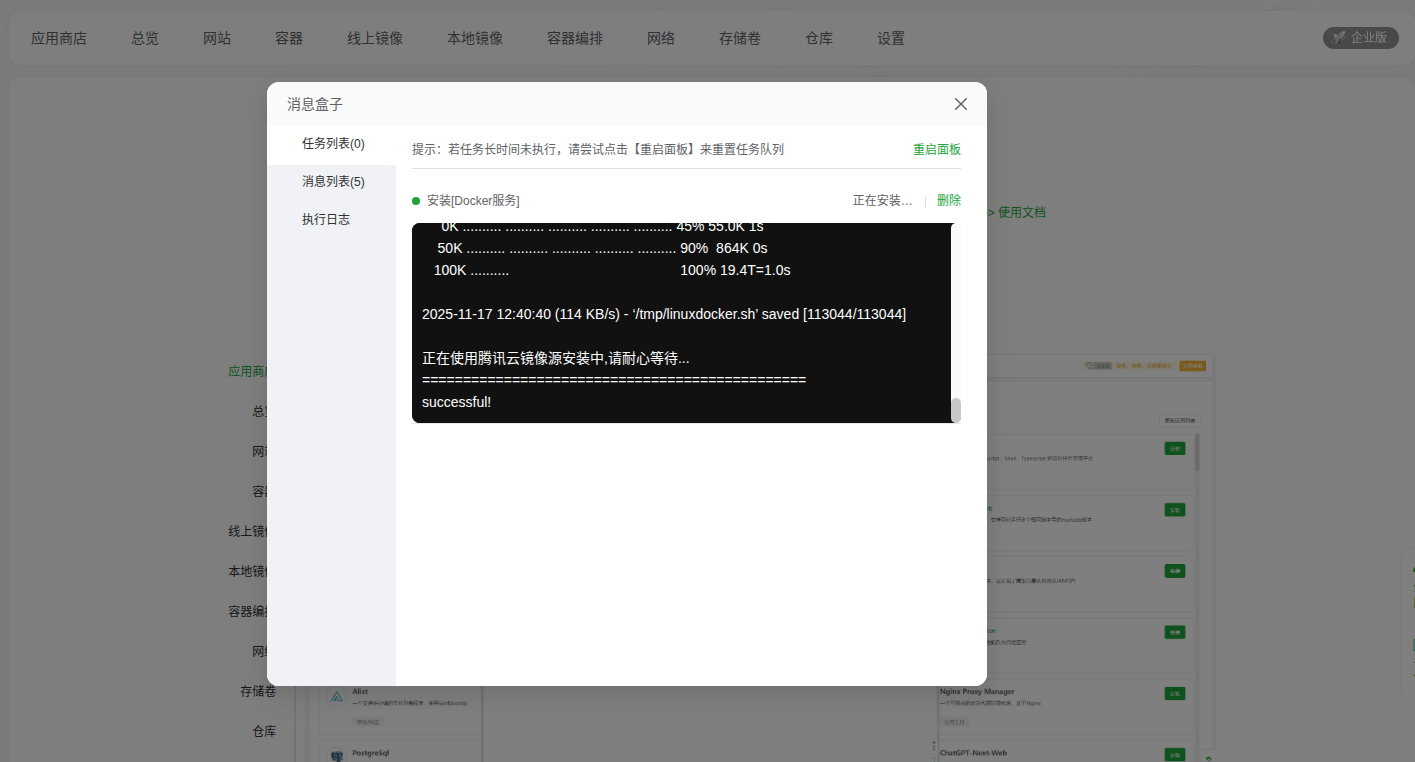
在DOCKER里安装NODEJS容器
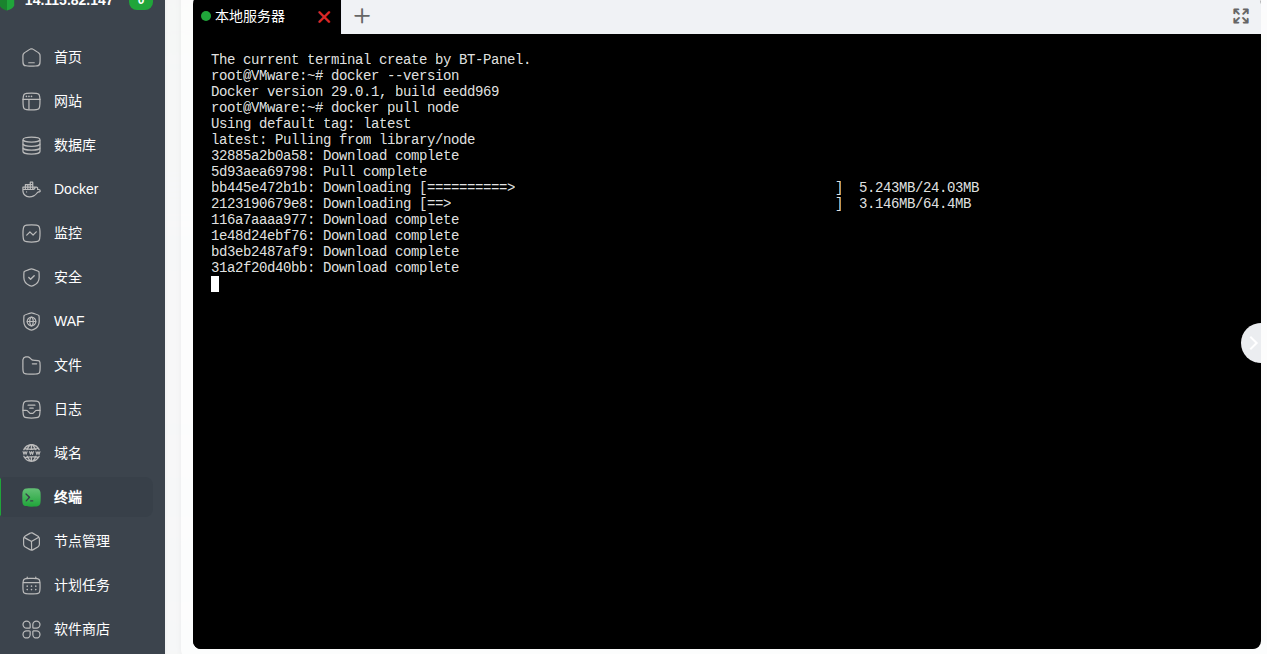
一.先查看一下docker的版本,验证一下
docker --version
通过DOCKER拉取NODEJS镜像到本地(直接拉的是latest版的)
1.通过终端安装
docker pull node
2.或者通过面板安装
这里可以自定义版本,比终端安装要方便些
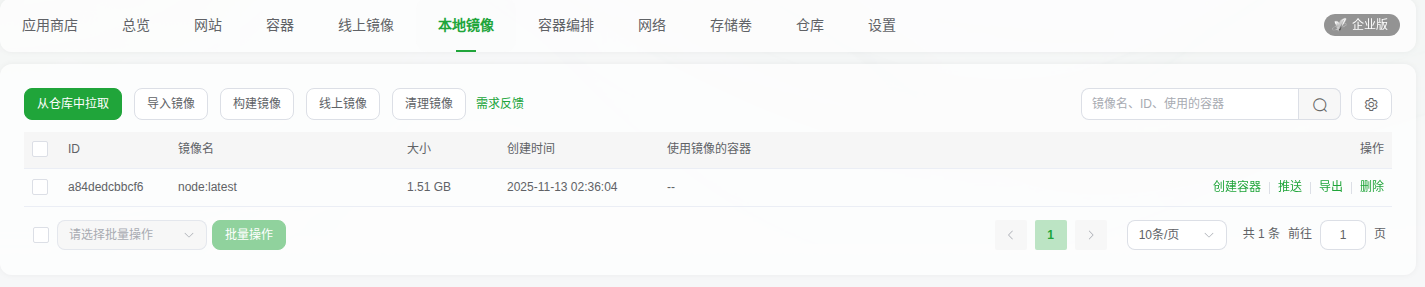
3.查看本地像镜是否安装成功
方案解析:可以把 Docker 想象成一个“集装箱”系统:
- 宿主机:是码头。
- Docker 镜像:是放在码头仓库里的、一个装满特定程序(Node.js)的“集装箱蓝图”。
- Docker 容器:是根据“蓝图”启动的一个正在运行的“集装箱”。
现在的情况是:码头(宿主机)本身没有 Node.js 程序,只是仓库里有一个装满 Node.js 的集装箱(镜像),但这个集装箱还没被打开和运行。
*NODEJS也是可以直装宿主机的,如:apt install nodejs,在这之前建议先apt update更新软件包,但LeePoet的选择是在 Docker 容器中运行 Node.js,因为这样的环境和管理更方便。刚刚操作就相当于码头(宿主机)本身没有 Nodejs 程序,只是仓库里有一个装满 Nodejs 的集装箱(镜像),但这个集装箱还没被打开和运行。
二、基础篇**
下面就基于已经拉取的node镜像启动一个容器在这个容器内安装HEXO,并将宿主机的一个目录“映射”到容器内,作为 Hexo 的工作目录。这样,所有 Hexo 项目文件都会保存在宿主机上,即使容器被删除,你的博客源码也不会丢失。更方便管理。
步骤一:准备宿主机工作目录
在宿主机上创建一个目录,用于存放 Hexo 博客项目。例如:
mkdir -p /home/leepoethexo
步骤二:创建并运行 Docker 容器
使用以下命令启动一个交互式容器,并将刚才创建的目录映射到容器内的一个路径(例如 /app)。
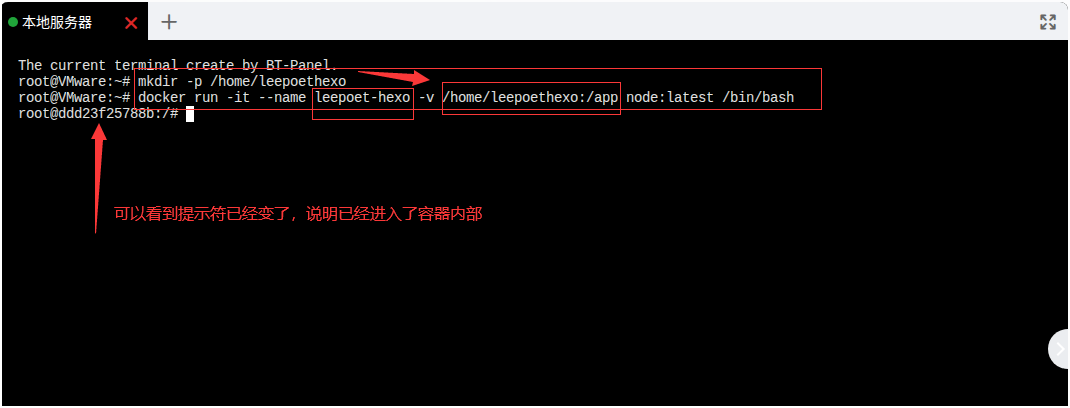
docker run -it --name leepoet-hexo -v /home/leepoethexo:/app node:latest /bin/bash
--name leepoet-hexo:为你创建的容器起一个有意义的名字,比如我取的是leepoet-hexo。-v /home/leepoethexo:/app:这是最关键的部分!-v参数将宿主机的/home/leepoethexo目录“挂载”到容器内的/app目录。两者内容完全同步。node:latest:指定使用你已有的 node 镜像。/bin/bash:启动容器后运行 shell,让你可以输入命令。
执行完这个命令后,会直接进入容器的命令行界面(提示符会变成 root@容器ID:/#)。
步骤三:在容器内安装 Hexo
现在,已经在容器内部了。接下来的操作都在容器内进行。
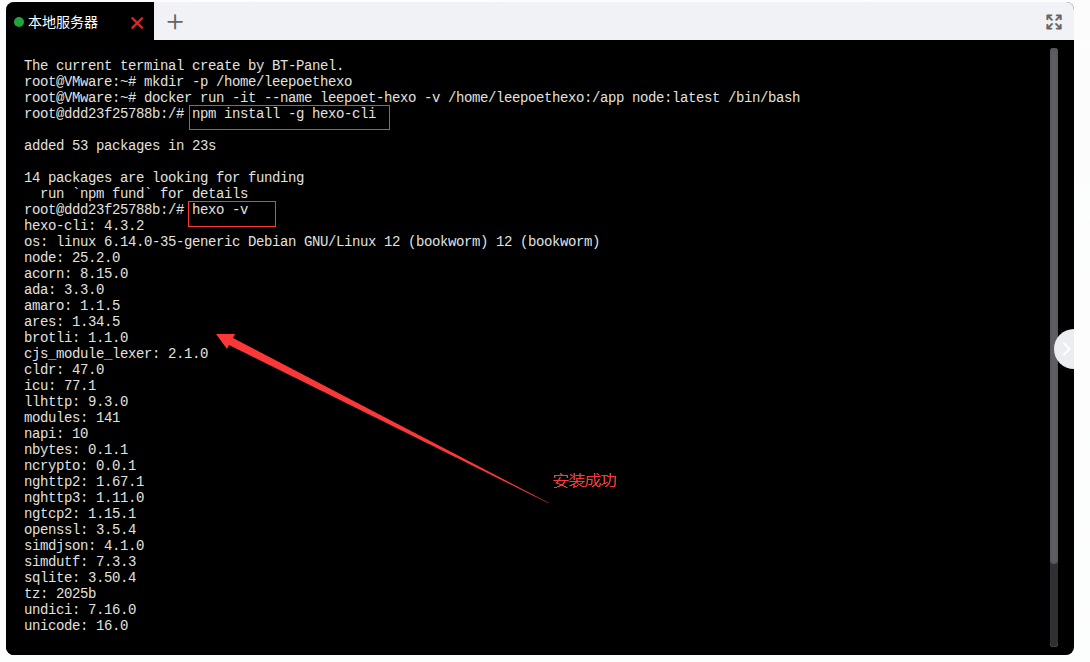
1.安装 Hexo 命令行工具:
npm install -g hexo-cli
2.(可选,但推荐)检查安装是否成功:
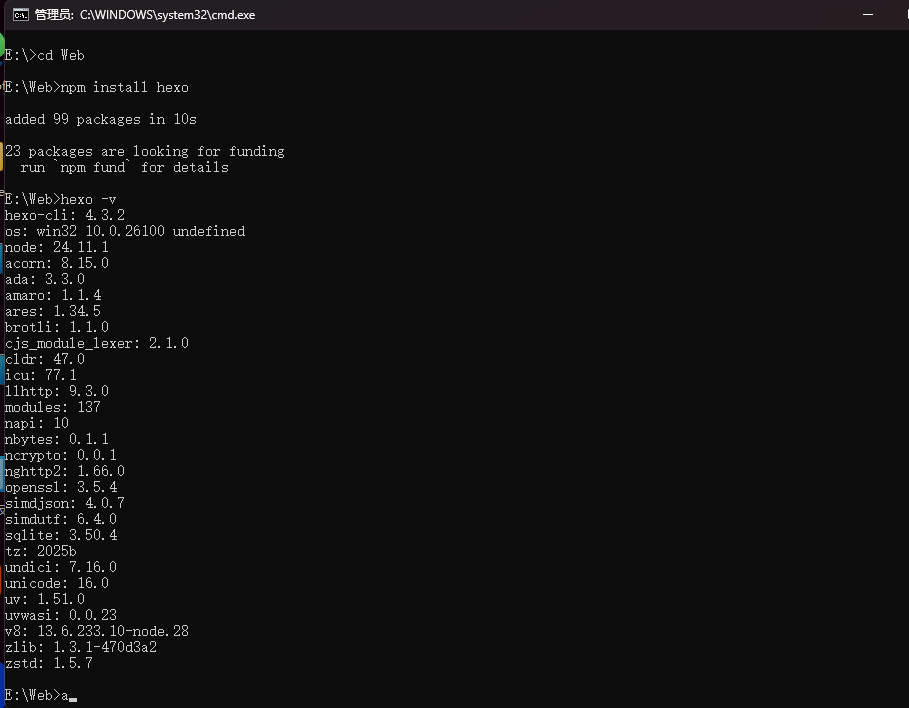
hexo -v
如果成功,会显示 Hexo 和 Node.js 的版本信息。
步骤四:初始化你的博客
重要:确保在容器内的 /app目录下操作,因为只有这个目录与宿主机是联通的。
1.进入挂载目录:
cd /app
2.初始化 Hexo 项目:
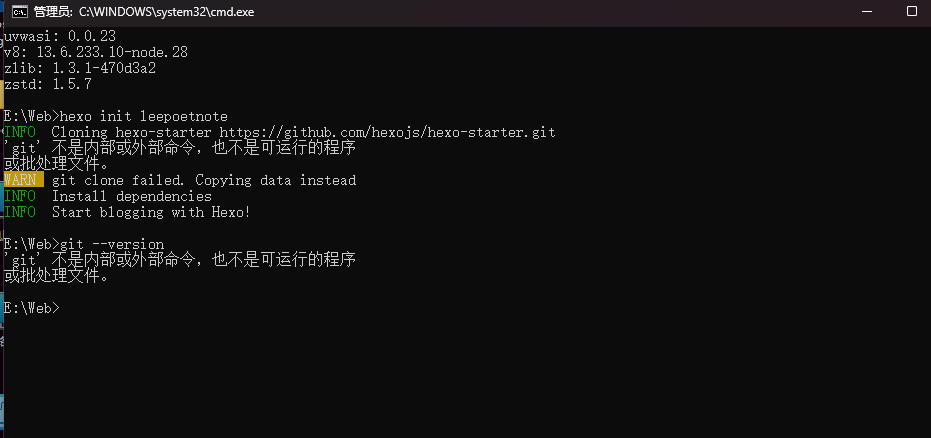
hexo init .
(注意命令最后有一个点 .,这表示在当前目录 /app初始化。)
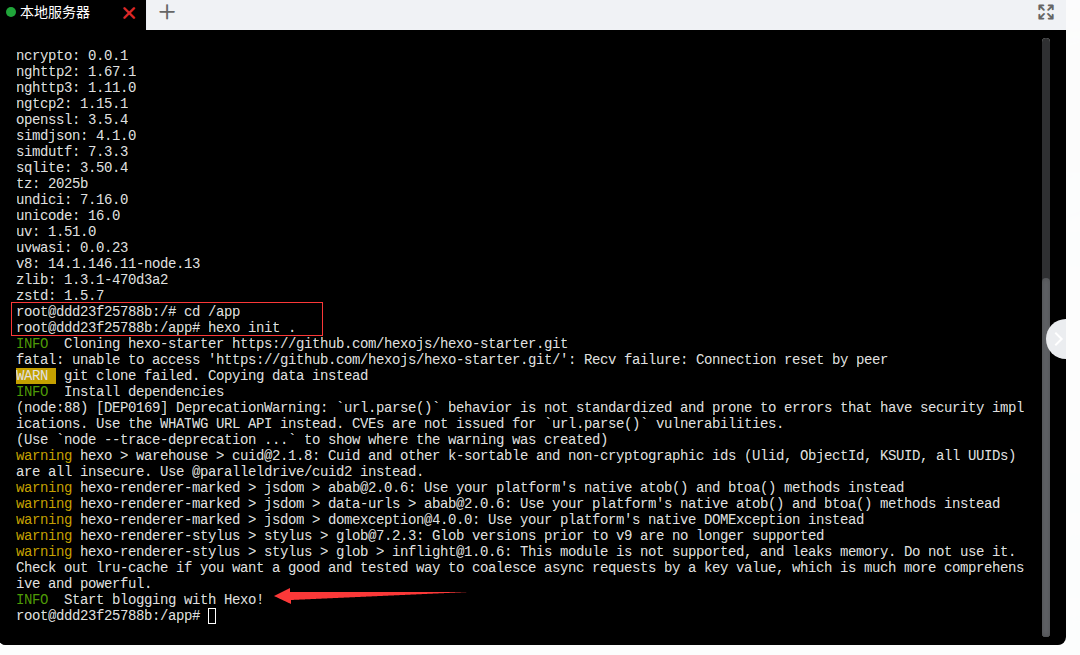
3.安装依赖包:
npm install
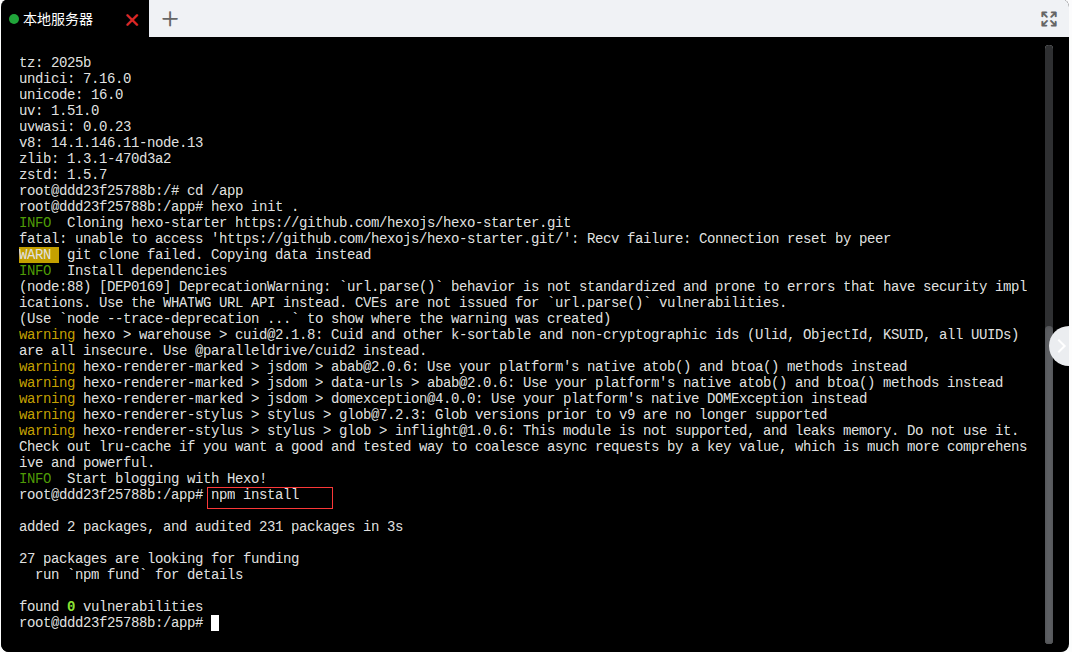
步骤五:测试运行
在容器内,使用 Hexo 命令启动本地服务器:
hexo server -s -p 4000
-s:静态模式。-p 4000:指定端口为 4000。
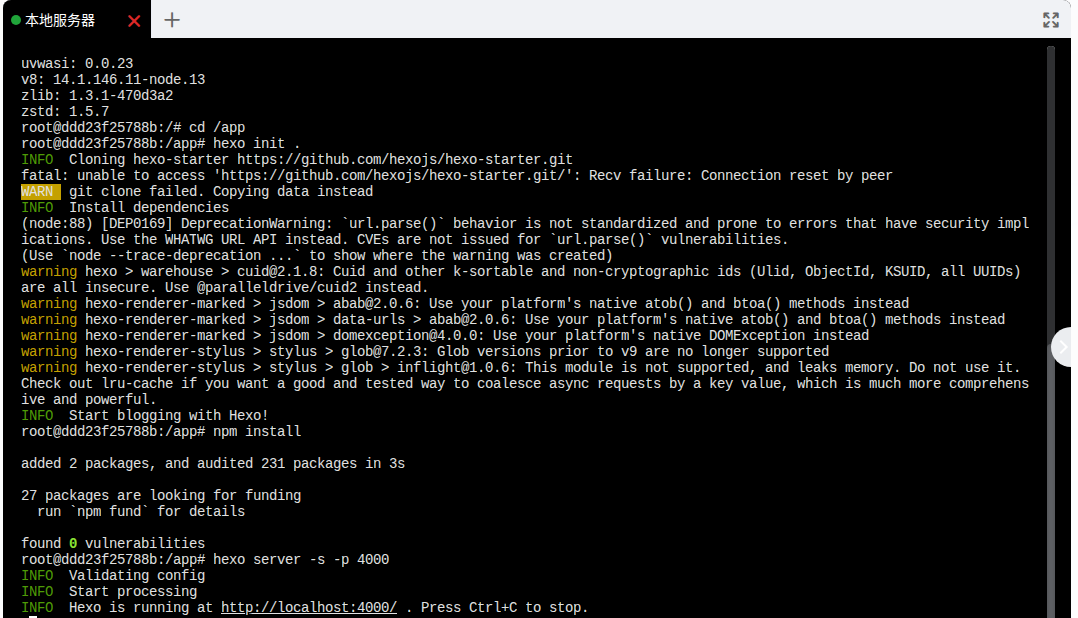
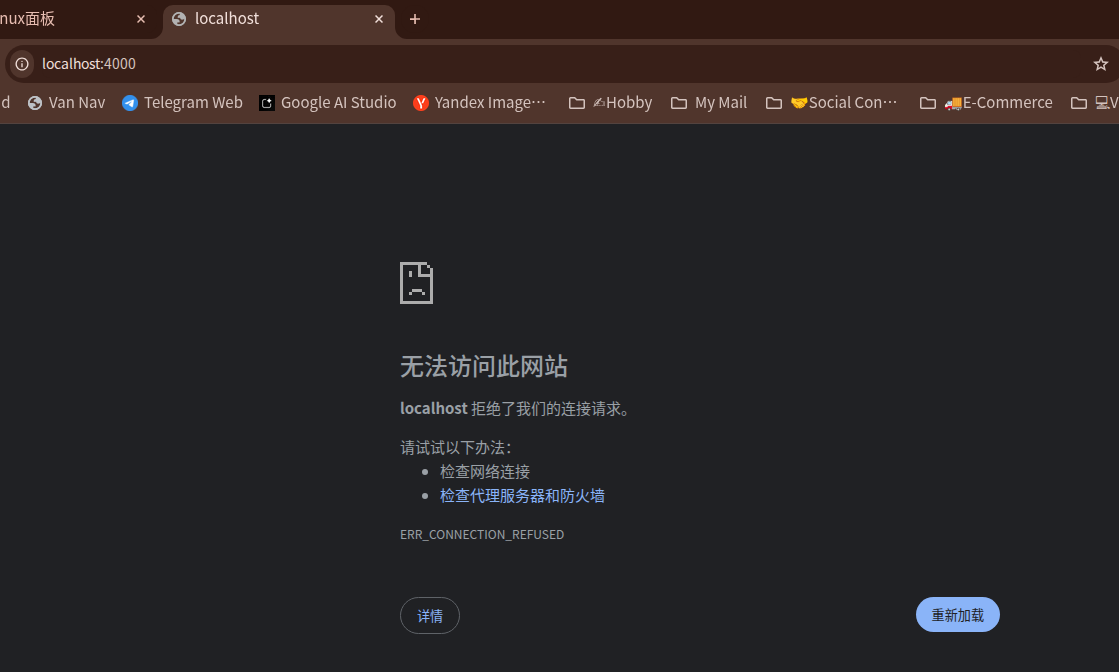
但是,此时还无法在宿主机上访问,因为容器的 4000 端口还没有映射到宿主机。
步骤六(重要):退出并重新创建容器以映射端口
现在需要一个更完善的容器,它既能持久化文件,又能映射端口。
1.退出当前容器:在容器命令行中输入 exit。
2.删除刚才创建的容器(别担心,博客文件在 /home/leepoethexo里很安全):
docker rm leepoet-hexo
*因为刚刚的容器名字我取的是“leepoet-blog”

*在docker rm leepoet-hexo我们可以通过docker ps -a参数查看所有容器。

3.重新创建一个“终极版”容器,同时映射端口和挂载目录:
docker run -it --name leepoet-hexo -p 4000:4000 -v /home/leepoethexo:/app node:latest /bin/bash
- 新增了
-p 4000:4000参数,将容器的 4000 端口映射到宿主机的 4000 端口。
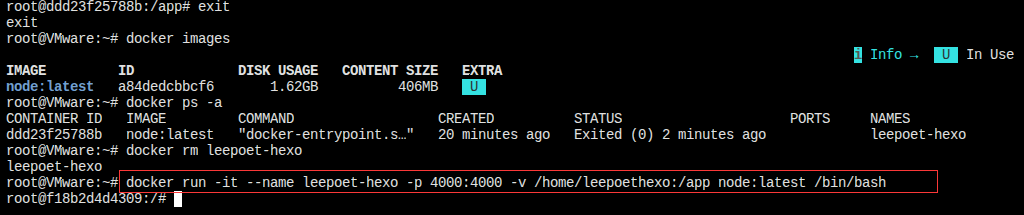
4.再次进入容器后,切换到 /app目录,启动服务器:
cd /app
npm install -g hexo-cli
hexo server -s -p 4000
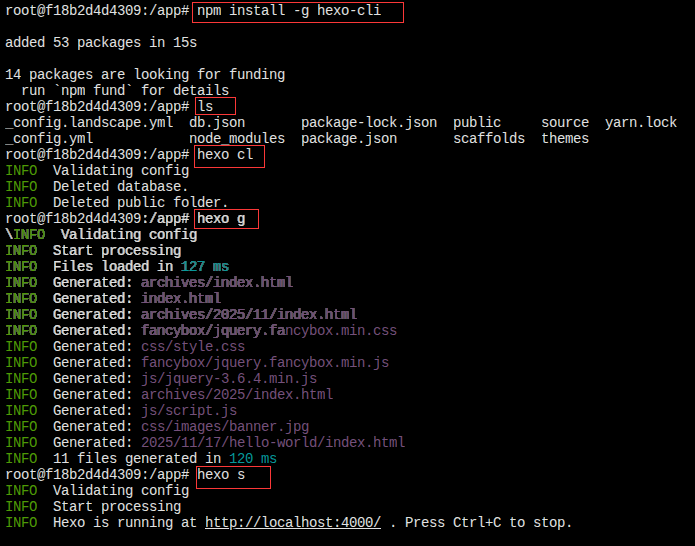
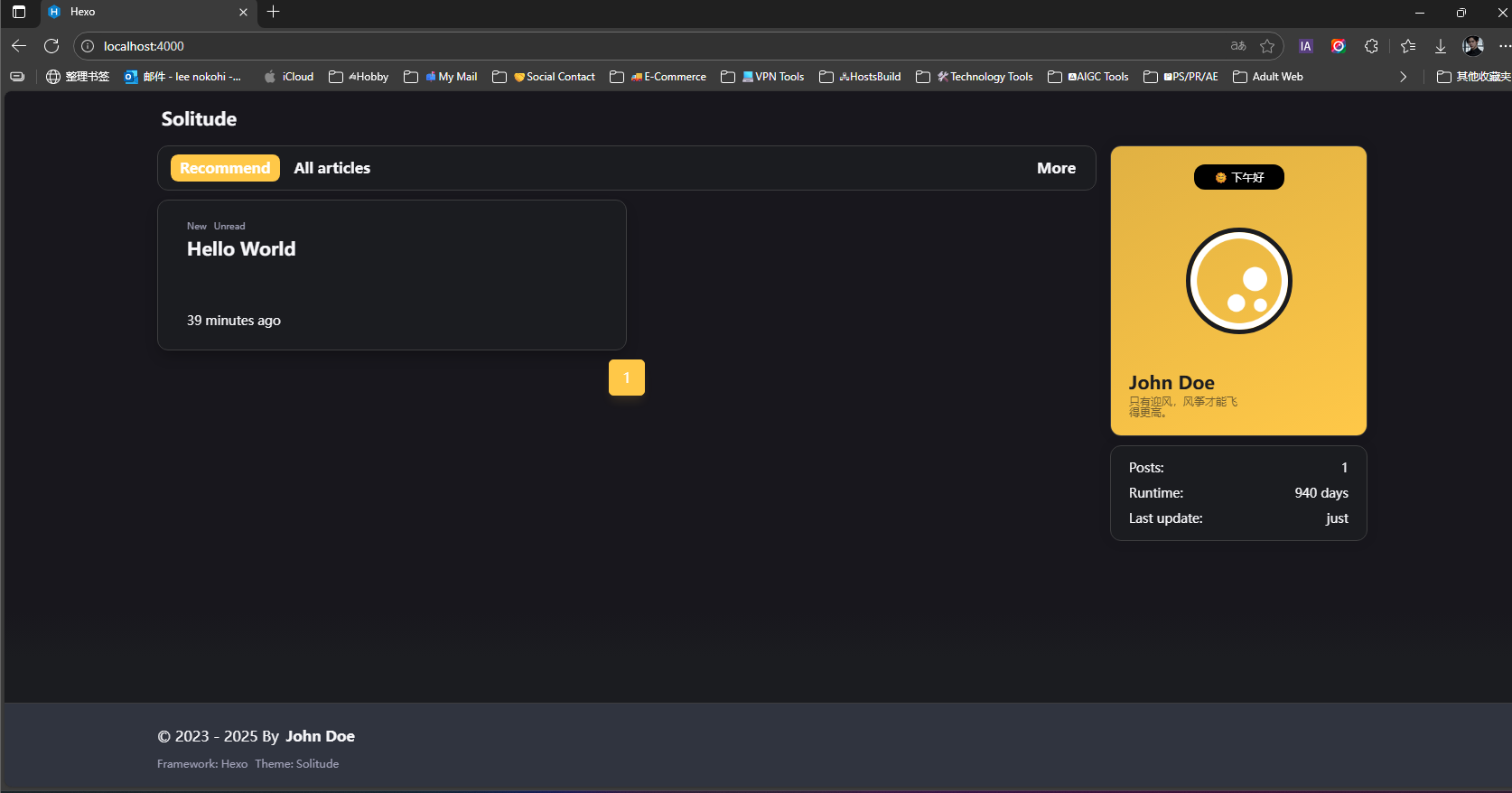
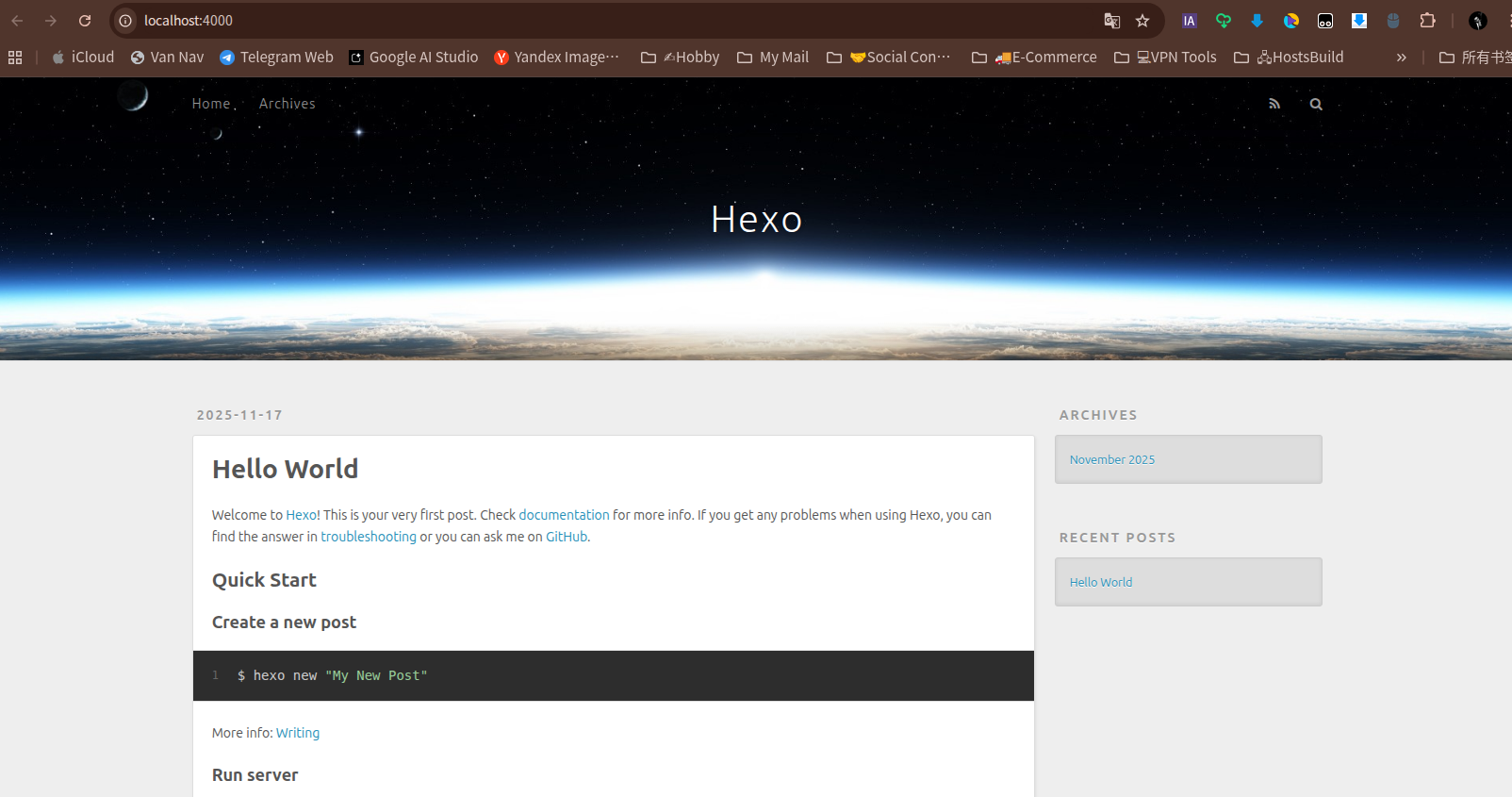
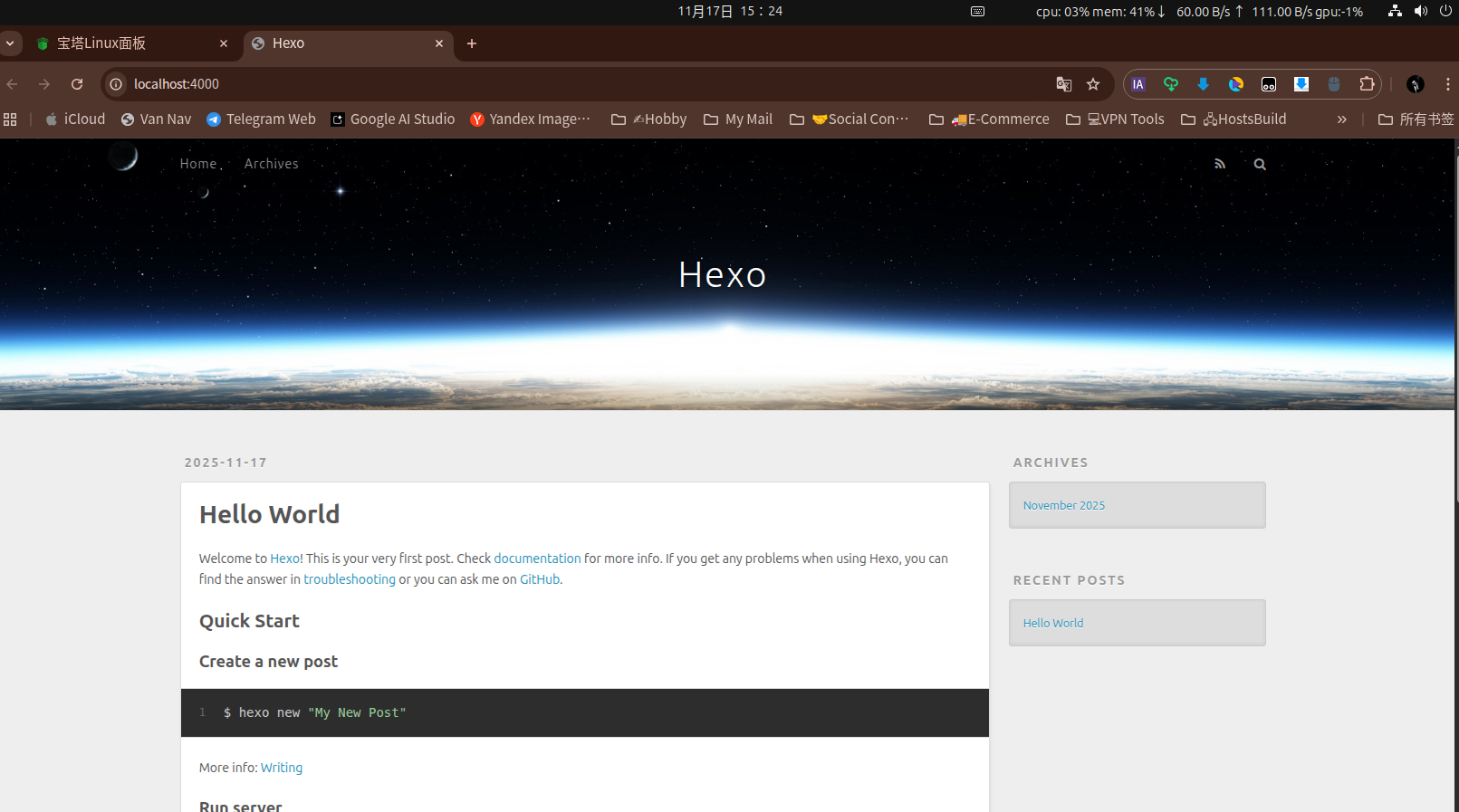
现在,你可以在宿主机的浏览器中访问 http://你的服务器IP:4000来查看 Hexo 博客了!
日常使用指南
- 启动已停止的容器:
docker start -i leepoet-hexo - 进入正在运行的容器(另开一个终端):
docker exec -it leepoet-hexo /bin/bash
这个方案的优势在于:
- 环境隔离:Hexo 和 Node.js 环境完全封装在容器内,不污染宿主机。
- 文件持久化:HEXO博客源码通过目录挂载安全地保存在宿主机上。
- 便于移植:只需拷贝
/home/hexo目录和docker run命令,就可以在任何有 Docker 的机器上快速恢复整个博客环境。
三、进阶篇
如果是服务器环境,解决权限问题:当使用 sudo或 root用户创建了网站目录 /www/wwwroot后,用普通用户账号登录去上传文件或修改网站内容时,系统可能会提示 “权限不足”。这是因为目录的所有者还是 root,普通用户没有写入权限。需要使用 /www/wwwroot作为宿主机的工作目录,来创建一个用于运行 Hexo 的 Docker 容器。这样在不使用 sudo的情况下,自由地在这个目录里创建、删除、修改文件和文件夹,大大方便了日常的网站维护工作。
整个流程的核心思路是:通过目录挂载,将宿主机的 /www/wwwroot目录与 Docker 容器内的 Hexo 工作目录关联起来,从而实现环境隔离、数据持久化和便捷管理。
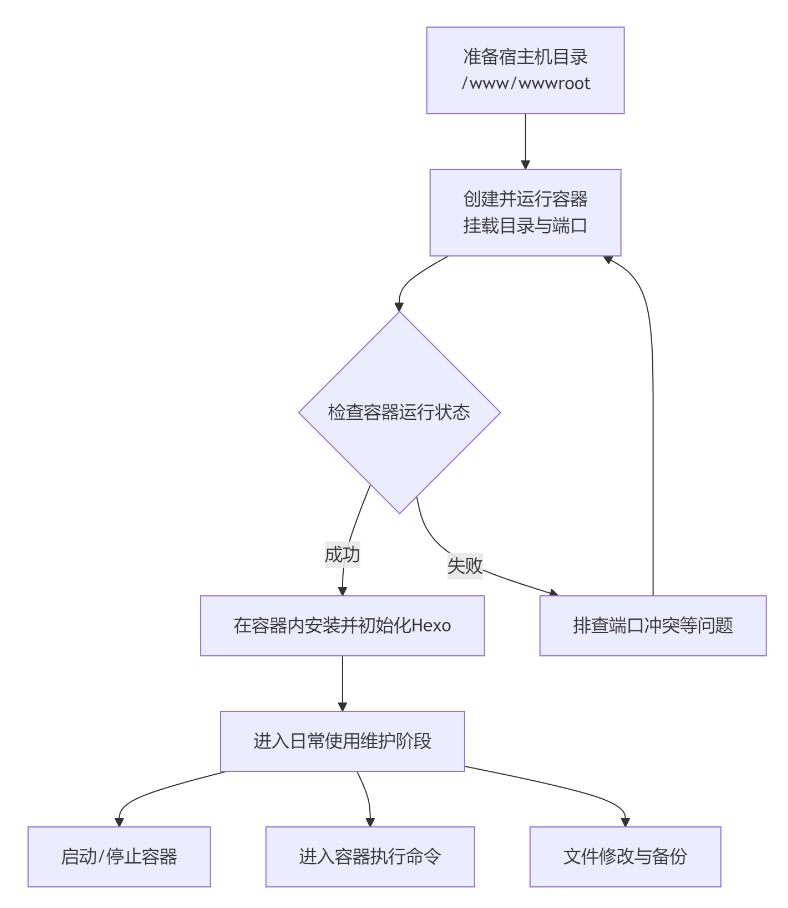
详细操作步骤
1. 准备宿主机目录
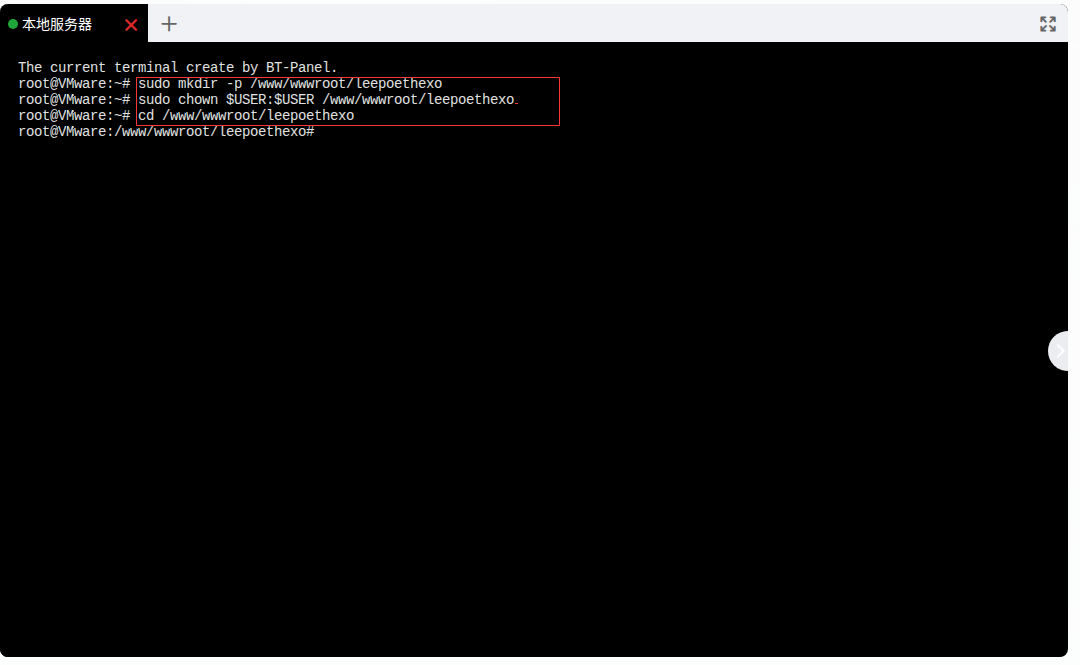
首先,确保宿主机上存在 /www/wwwroot/leepoethexo目录。如果不存在,可以创建它并设置适当的权限:
sudo mkdir -p /www/wwwroot/leepoethexo
sudo chown $USER:$USER /www/wwwroot/leepoethexo # 将目录所有者改为当前用户,方便操作
或者
sudo chmod -R 755 /www/wwwroot/leepoethexo #目录所有者可完全读写执行,其他用户只能读和执行。这是Web目录更常用的安全权限
cd /www/wwwroot/leepoethexo
2. 创建并运行Docker容器
这是最关键的一步。我们将使用 docker run命令,并通过 -v参数将宿主机目录挂载到容器内,同时用 -p参数映射端口,方便调试和访问。
执行以下命令来创建并运行一个名为 leepoet-hexo的容器:
docker run -d -it \
--name leepoet-hexo \
-p 4000:4000 \
-v /www/wwwroot/leepoethexo:/app \
node:latest \
/bin/bash -c "tail -f /dev/null"
参数解释:
-d -it: 以交互式终端并在后台运行容器。--name leepoet-hexo: 为容器起个名字,方便后续管理。-p 4000:4000: 将容器的4000端口(Hexo服务器默认端口)映射到宿主机的4000端口。这样就能通过http://你的服务器IP:4000访问博客了。-v /www/wwwroot/leepoethexo:/app: 这就是目录挂载。它将宿主机的/www/wwwroot/leepoethexo目录关联到容器内的/app目录。你在容器内/app下的所有操作,都会实时同步到宿主机的/www/wwwroot/leepoethexo下。node:latest: 使用已有的 Node.js 镜像。tail -f /dev/null: 一个让容器保持运行的小技巧。

3. 在容器内安装和初始化Hexo
现在,容器已经在后台运行了。我们需要进入容器内部完成Hexo的安装。
a. 进入容器:
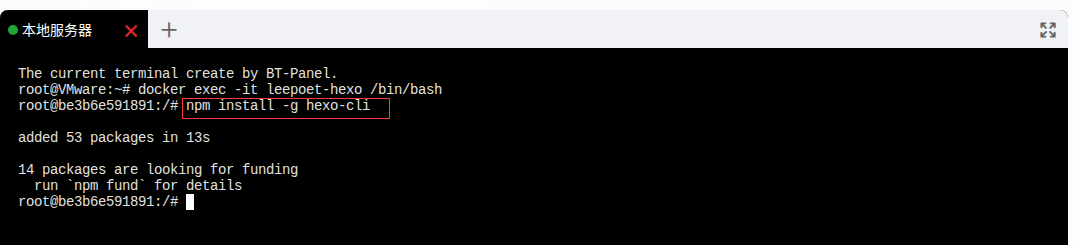
docker exec -it leepoet-hexo /bin/bash

执行后,你的命令行提示符会变成类似 root@容器ID:/#的样子,表示你已经进入了容器内部。
b. 全局安装Hexo命令行工具:
npm install -g hexo-cli
c. 初始化Hexo项目:
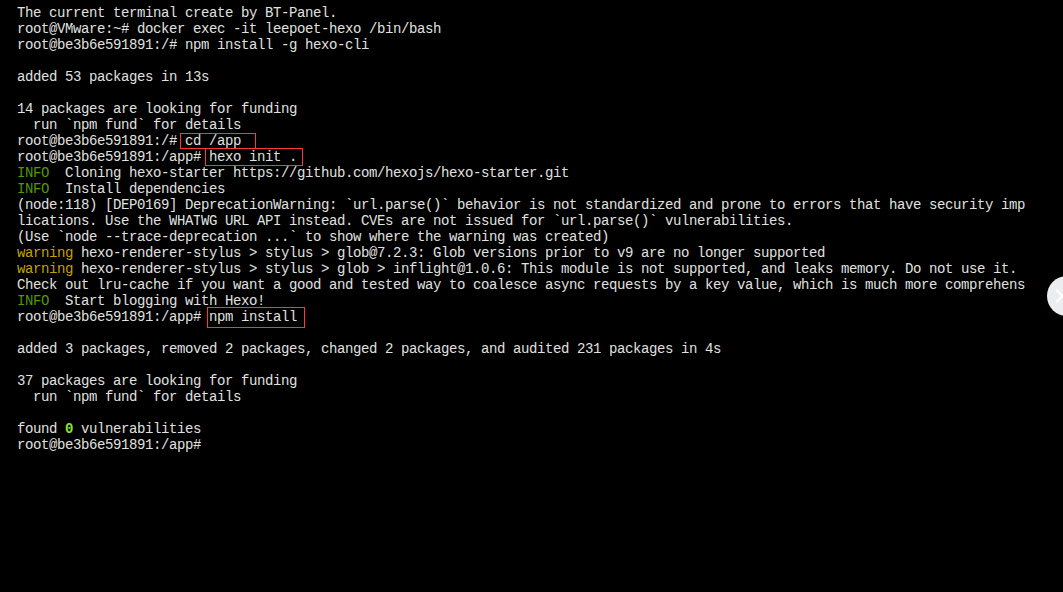
cd /app # 这是挂载点,务必在此目录下操作!
hexo init . # 注意最后有个点,表示在当前目录初始化
npm install # 安装Hexo所需的依赖包
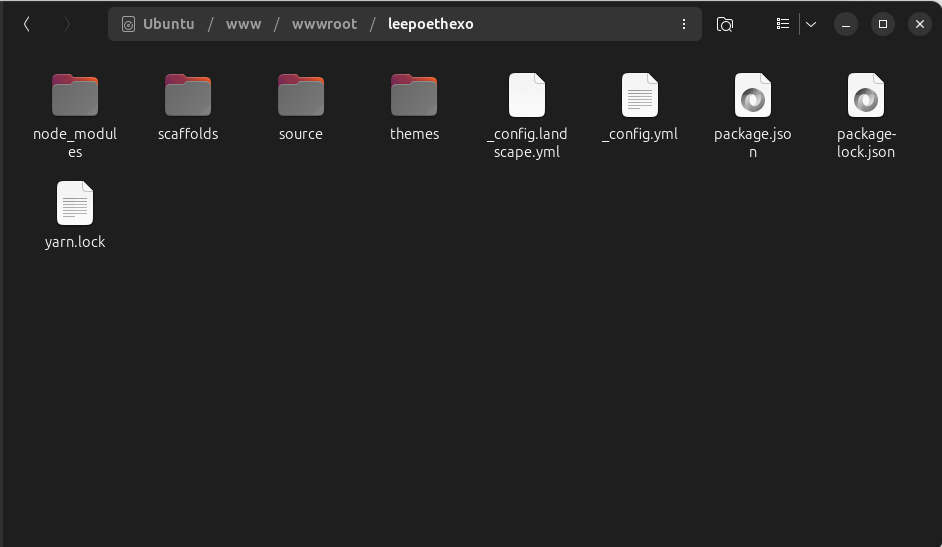
初始化完成后,你会在宿主机的 /www/wwwroot/leepoethexo目录下看到Hexo的项目文件。
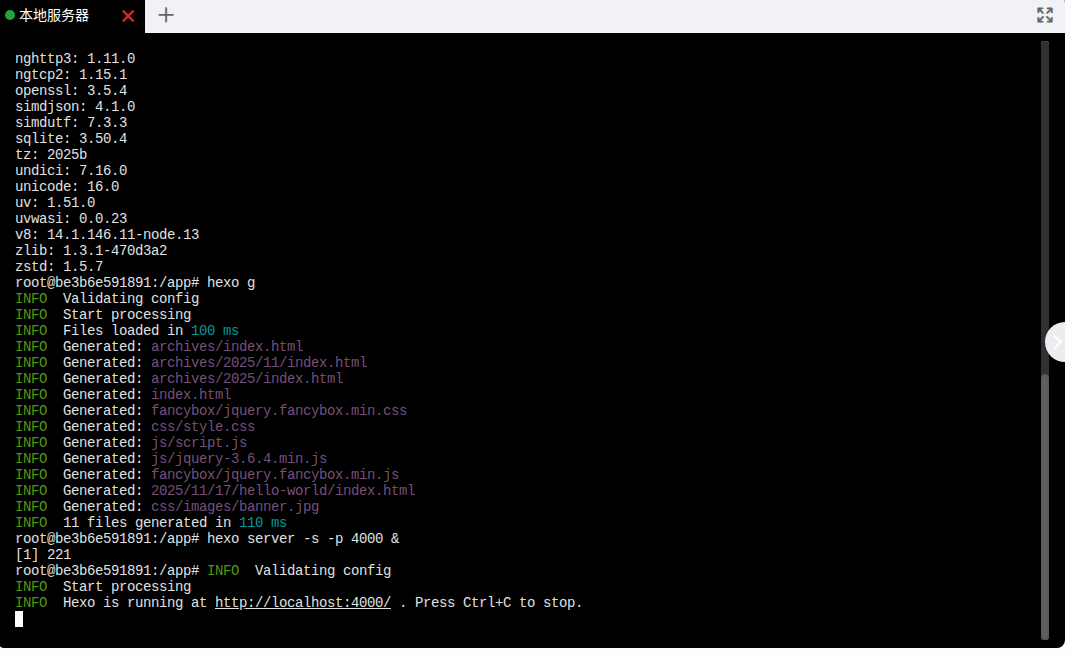
d. 生成静态文件并启动本地服务器(在容器内执行):
hexo generate
hexo server -s -p 4000 &
现在,你应该可以在宿主机的浏览器中访问 http://localhost:4000看到默认的Hexo博客页面了。
日常使用指南
当环境搭建好后,你通常会进行以下操作:
| 操作场景 | 命令 | 说明 |
|---|---|---|
| 启动已停止的容器 | docker start leepoet-hexo | 容器停止后,用它重新启动。 |
| 进入容器 | docker exec -it leepoet-hexo /bin/bash | 进入容器内部执行命令(如写作、安装插件)。 |
| 停止容器 | docker stop leepoet-hexo | 正常停止容器。 |
| 查看容器日志 | docker logs leepoet-hexo | 排查问题时查看输出信息。 |
| 在宿主机上编辑 | 用你的IDE直接编辑 /www/wwwroot/leepoethexo下的文件 | 所有更改会实时同步到容器内。 |
exec:表示在容器内执行命令。-it:这是两个选项的组合。-i(--interactive) 保持标准输入流开放,允许你输入命令;-t(--tty) 分配一个伪终端,让你获得一个格式良好的交互式 Shell 体验。leepoet-hexo:是你的容器名称。如果你当时创建时用了其他名字,这里需要替换掉。/bin/bash:指定在容器内运行的 Shell 程序(这里指 Bash)。- 重要优点:使用
exec方式进入容器,当你输入exit退出时,只会结束当前的 Shell 会话,而不会导致你的 Hexo 容器停止运行。这对于需要长期运行的服务(比如你的博客服务器)至关重要。
常用Hexo命令(在容器内执行):
hexo new "我的新文章" # 创建一篇新文章
hexo clean # 清理缓存
hexo generate # 生成静态文件
hexo deploy # 部署到服务器
hexo server -s -p 4000 # 启动本地服务器进行预览
hexo generate --debug # 启用调试模式
hexo g --debug # 或简写
hexo g --verbose # 查看每个文件的处理情况
hexo g --debug --verbose # 同时启用调试和详细模式
方案优势与注意事项
这个方案的优势在于:
•数据持久化:你的所有Hexo博客源文件都安全地保存在宿主机的 /www/wwwroot/leepoethexo目录下。即使你删除了Docker容器,你的博客源码也不会丢失。
•环境隔离:Hexo的运行环境被封装在容器内,不会污染宿主机系统。
•便捷开发:你可以在宿主机上用熟悉的编辑器修改 /www/wwwroot/leepoethexo下的文件,更改会立刻在容器中生效,无需反复进入容器。
需要注意的事项:
•权限问题:如果遇到容器内进程没有权限写入挂载目录的情况,可能需要检查宿主机目录( )的权限设置/www/wwwroot/leepoethexo
•端口占用:确保宿主的4000端口没有被其他程序占用。
•备份:虽然源码已在宿主机上,但定期备份整个 /www/wwwroot/leepoethexo目录是一个好习惯。
往期有关HEXO教程: